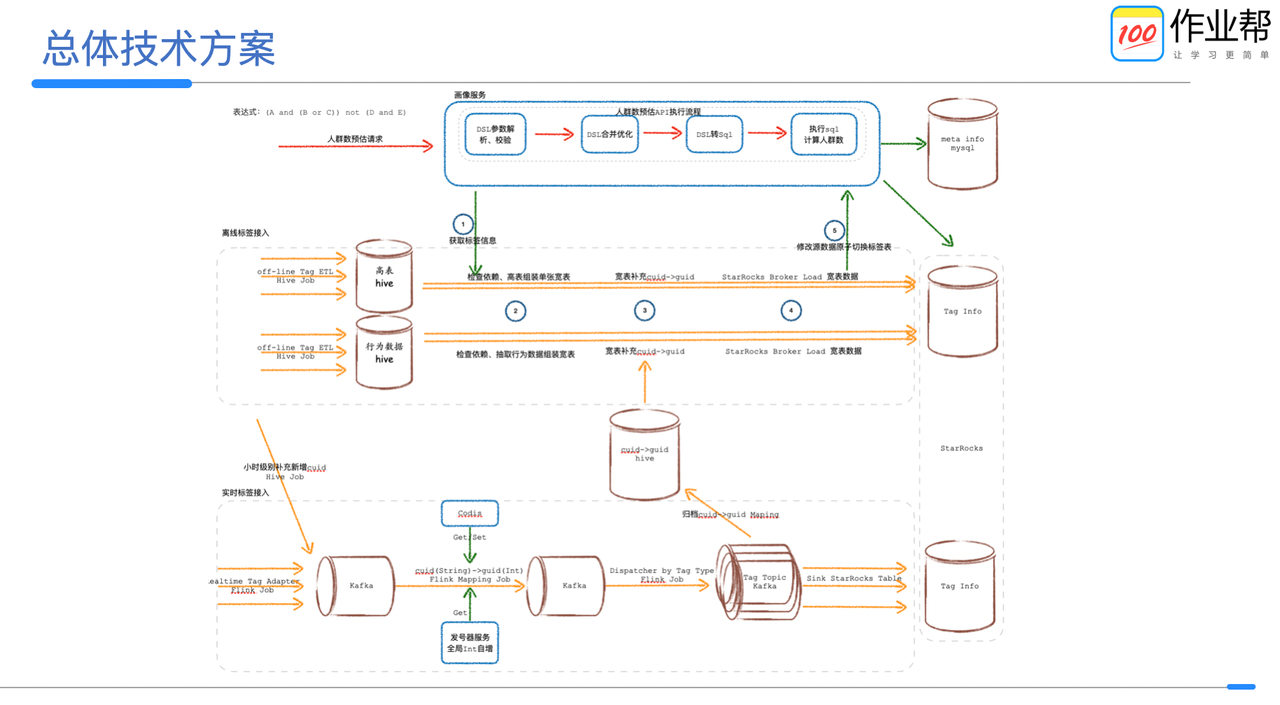
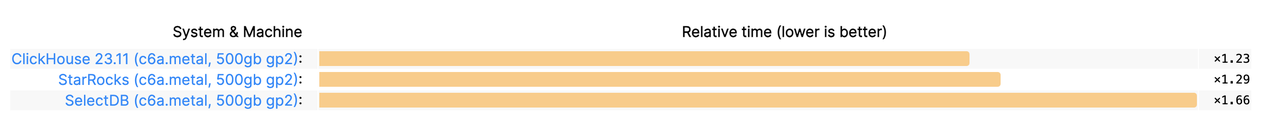| Load time: |
加载时间 |
132s (×1.00) |
369s (×2.80) |
433s (×3.29) |
369s (×2.80) |
433s (×3.29) |
132s (×1.00) |
| Data size: |
数据大小 |
13.47 GiB (×1.00) |
15.95 GiB (×1.18) |
16.49 GiB (×1.22) |
15.95 GiB (×1.18) |
16.49 GiB (×1.22) |
13.47 GiB (×1.00) |
| SELECT COUNT(*) FROM hits; |
count |
0.00s (×1.00) |
0.03s (×3.08) |
0.00s (×0.77) |
0.01s (×1.00) |
0.04s (×2.50) |
0.06s (×3.55) |
| SELECT COUNT(*) FROM hits WHERE AdvEngineID <> 0; |
count |
0.01s (×1.00) |
0.03s (×1.82) |
0.02s (×1.36) |
0.03s (×1.48) |
0.12s (×4.81) |
0.02s (×1.00) |
| SELECT SUM(AdvEngineID), COUNT(*), AVG(ResolutionWidth) FROM hits; |
汇总函数 |
0.02s (×1.00) |
0.06s (×2.41) |
0.04s (×1.72) |
0.04s (×1.00) |
0.66s (×13.40) |
0.05s (×1.16) |
| SELECT AVG(UserID) FROM hits; |
汇总函数 |
0.02s (×1.00) |
0.06s (×2.33) |
0.06s (×2.33) |
0.07s (×1.00) |
2.08s (×26.12) |
0.71s (×9.06) |
| SELECT COUNT(DISTINCT UserID) FROM hits; |
去重 |
0.20s (×2.32) |
0.08s (×1.00) |
0.15s (×1.78) |
0.17s (×1.64) |
0.10s (×1.00) |
0.88s (×8.10) |
| SELECT COUNT(DISTINCT SearchPhrase) FROM hits; |
去重 |
0.17s (×1.00) |
0.21s (×1.19) |
0.28s (×1.57) |
0.30s (×1.00) |
2.19s (×7.10) |
1.09s (×3.56) |
| SELECT MIN(EventDate), MAX(EventDate) FROM hits; |
汇总函数 |
0.02s (×1.35) |
0.02s (×1.50) |
0.01s (×1.00) |
0.01s (×1.00) |
0.04s (×2.50) |
0.02s (×1.50) |
| SELECT AdvEngineID, COUNT() FROM hits WHERE AdvEngineID <> 0 GROUP BY AdvEngineID ORDER BY COUNT() DESC; |
分桶 |
0.02s (×1.13) |
0.04s (×1.67) |
0.02s (×1.00) |
0.02s (×1.00) |
0.06s (×2.33) |
0.04s (×1.67) |
| SELECT RegionID, COUNT(DISTINCT UserID) AS u FROM hits GROUP BY RegionID ORDER BY u DESC LIMIT 10; |
分桶 |
0.26s (×2.10) |
0.12s (×1.00) |
0.33s (×2.62) |
0.32s (×1.00) |
0.99s (×3.03) |
0.87s (×2.67) |
| SELECT RegionID, SUM(AdvEngineID), COUNT(*) AS c, AVG(ResolutionWidth), COUNT(DISTINCT UserID) FROM hits GROUP BY RegionID ORDER BY c DESC LIMIT 10; |
分桶 |
0.27s (×1.00) |
0.70s (×2.55) |
0.34s (×1.26) |
0.36s (×1.00) |
0.73s (×2.00) |
1.14s (×3.10) |
| SELECT MobilePhoneModel, COUNT(DISTINCT UserID) AS u FROM hits WHERE MobilePhoneModel <> ‘’ GROUP BY MobilePhoneModel ORDER BY u DESC LIMIT 10; |
分桶 |
0.09s (×1.60) |
0.05s (×1.00) |
0.11s (×2.00) |
0.11s (×1.00) |
0.13s (×1.17) |
0.38s (×3.27) |
| SELECT MobilePhone, MobilePhoneModel, COUNT(DISTINCT UserID) AS u FROM hits WHERE MobilePhoneModel <> ‘’ GROUP BY MobilePhone, MobilePhoneModel ORDER BY u DESC LIMIT 10; |
分桶 |
0.09s (×1.49) |
0.06s (×1.00) |
0.10s (×1.57) |
0.11s (×1.00) |
1.04s (×8.75) |
0.74s (×6.23) |
| SELECT SearchPhrase, COUNT(*) AS c FROM hits WHERE SearchPhrase <> ‘’ GROUP BY SearchPhrase ORDER BY c DESC LIMIT 10; |
分桶 |
0.16s (×1.00) |
0.17s (×1.05) |
0.23s (×1.40) |
0.23s (×1.33) |
0.17s (×1.00) |
1.25s (×7.00) |
| SELECT SearchPhrase, COUNT(DISTINCT UserID) AS u FROM hits WHERE SearchPhrase <> ‘’ GROUP BY SearchPhrase ORDER BY u DESC LIMIT 10; |
分桶 |
0.19s (×1.00) |
0.23s (×1.22) |
0.75s (×3.88) |
0.55s (×2.33) |
0.23s (×1.00) |
1.91s (×7.99) |
| SELECT SearchEngineID, SearchPhrase, COUNT(*) AS c FROM hits WHERE SearchPhrase <> ‘’ GROUP BY SearchEngineID, SearchPhrase ORDER BY c DESC LIMIT 10; |
分桶 |
0.16s (×1.00) |
0.18s (×1.10) |
0.30s (×1.79) |
0.32s (×1.00) |
0.54s (×1.67) |
1.24s (×3.78) |
| SELECT UserID, COUNT() FROM hits GROUP BY UserID ORDER BY COUNT() DESC LIMIT 10; |
分桶 |
0.12s (×1.43) |
0.08s (×1.00) |
0.16s (×1.89) |
0.18s (×1.90) |
0.09s (×1.00) |
0.50s (×5.12) |
| SELECT UserID, SearchPhrase, COUNT() FROM hits GROUP BY UserID, SearchPhrase ORDER BY COUNT() DESC LIMIT 10; |
分桶 |
0.34s (×1.14) |
0.30s (×1.00) |
0.50s (×1.65) |
0.53s (×1.69) |
0.31s (×1.00) |
2.06s (×6.45) |
| SELECT UserID, SearchPhrase, COUNT(*) FROM hits GROUP BY UserID, SearchPhrase LIMIT 10; |
分桶 |
0.24s (×2.28) |
0.10s (×1.00) |
0.20s (×1.91) |
0.20s (×1.62) |
0.12s (×1.00) |
1.58s (×12.27) |
| SELECT UserID, extract(minute FROM EventTime) AS m, SearchPhrase, COUNT() FROM hits GROUP BY UserID, m, SearchPhrase ORDER BY COUNT() DESC LIMIT 10; |
分桶 |
0.61s (×1.38) |
0.44s (×1.00) |
1.06s (×2.38) |
1.04s (×1.00) |
1.27s (×1.22) |
3.67s (×3.50) |
| SELECT UserID FROM hits WHERE UserID = 435090932899640449; |
点查 |
0.01s (×1.05) |
0.00s (×0.50) |
0.00s (×0.50) |
0.01s (×1.00) |
0.01s (×1.00) |
0.09s (×5.00) |
| SELECT COUNT(*) FROM hits WHERE URL LIKE ‘%google%’; |
模糊搜索 |
0.13s (×1.00) |
0.15s (×1.19) |
0.60s (×4.52) |
0.59s (×1.00) |
12.09s (×20.17) |
9.27s (×15.46) |
| SELECT SearchPhrase, MIN(URL), COUNT(*) AS c FROM hits WHERE URL LIKE ‘%google%’ AND SearchPhrase <> ‘’ GROUP BY SearchPhrase ORDER BY c DESC LIMIT 10; |
模糊搜索 |
0.17s (×1.35) |
0.12s (×1.00) |
0.34s (×2.69) |
0.48s (×2.72) |
0.17s (×1.00) |
10.93s (×60.77) |
| SELECT SearchPhrase, MIN(URL), MIN(Title), COUNT(*) AS c, COUNT(DISTINCT UserID) FROM hits WHERE Title LIKE ‘%Google%’ AND URL NOT LIKE ‘%.google.%’ AND SearchPhrase <> ‘’ GROUP BY SearchPhrase ORDER BY c DESC LIMIT 10; |
模糊搜索 |
0.22s (×1.00) |
0.24s (×1.11) |
0.37s (×1.68) |
0.38s (×1.00) |
10.91s (×28.00) |
13.05s (×33.50) |
| SELECT * FROM hits WHERE URL LIKE ‘%google%’ ORDER BY EventTime LIMIT 10; |
模糊搜索 |
0.59s (×2.31) |
0.86s (×3.35) |
0.25s (×1.00) |
0.25s (×1.00) |
28.25s (×108.69) |
36.63s (×140.92) |
| SELECT SearchPhrase FROM hits WHERE SearchPhrase <> ‘’ ORDER BY EventTime LIMIT 10; |
排序 |
0.04s (×1.83) |
0.02s (×1.00) |
0.04s (×1.67) |
0.04s (×1.25) |
0.03s (×1.00) |
2.02s (×50.85) |
| SELECT SearchPhrase FROM hits WHERE SearchPhrase <> ‘’ ORDER BY SearchPhrase LIMIT 10; |
排序 |
0.04s (×1.02) |
0.04s (×1.00) |
0.14s (×3.00) |
0.15s (×2.29) |
0.06s (×1.00) |
1.33s (×19.09) |
| SELECT SearchPhrase FROM hits WHERE SearchPhrase <> ‘’ ORDER BY EventTime, SearchPhrase LIMIT 10; |
排序 |
0.05s (×2.00) |
0.02s (×1.00) |
0.04s (×1.67) |
0.04s (×1.67) |
0.02s (×1.00) |
2.71s (×90.63) |
| SELECT CounterID, AVG(length(URL)) AS l, COUNT() AS c FROM hits WHERE URL <> ‘’ GROUP BY CounterID HAVING COUNT() > 100000 ORDER BY l DESC LIMIT 25; |
having |
0.25s (×1.18) |
0.21s (×1.00) |
0.54s (×2.50) |
0.55s (×1.00) |
0.63s (×1.14) |
9.63s (×17.22) |
| SELECT REGEXP_REPLACE(Referer, ‘^https?://(?:www.)?([^/]+)/.$’, ‘\1’) AS k, AVG(length(Referer)) AS l, COUNT() AS c, MIN(Referer) FROM hits WHERE Referer <> ‘’ GROUP BY k HAVING COUNT(*) > 100000 ORDER BY l DESC LIMIT 25; |
having |
1.19s (×1.00) |
1.60s (×1.34) |
1.34s (×1.12) |
1.39s (×1.00) |
8.77s (×6.27) |
8.05s (×5.76) |
| SELECT SUM(ResolutionWidth), SUM(ResolutionWidth + 1), SUM(ResolutionWidth + 2), SUM(ResolutionWidth + 3), SUM(ResolutionWidth + 4), SUM(ResolutionWidth + 5), SUM(ResolutionWidth + 6), SUM(ResolutionWidth + 7), SUM(ResolutionWidth + 8), SUM(ResolutionWidth + 9), SUM(ResolutionWidth + 10), SUM(ResolutionWidth + 11), SUM(ResolutionWidth + 12), SUM(ResolutionWidth + 13), SUM(ResolutionWidth + 14), SUM(ResolutionWidth + 15), SUM(ResolutionWidth + 16), SUM(ResolutionWidth + 17), SUM(ResolutionWidth + 18), SUM(ResolutionWidth + 19), SUM(ResolutionWidth + 20), SUM(ResolutionWidth + 21), SUM(ResolutionWidth + 22), SUM(ResolutionWidth + 23), SUM(ResolutionWidth + 24), SUM(ResolutionWidth + 25), SUM(ResolutionWidth + 26), SUM(ResolutionWidth + 27), SUM(ResolutionWidth + 28), SUM(ResolutionWidth + 29), SUM(ResolutionWidth + 30), SUM(ResolutionWidth + 31), SUM(ResolutionWidth + 32), SUM(ResolutionWidth + 33), SUM(ResolutionWidth + 34), SUM(ResolutionWidth + 35), SUM(ResolutionWidth + 36), SUM(ResolutionWidth + 37), SUM(ResolutionWidth + 38), SUM(ResolutionWidth + 39), SUM(ResolutionWidth + 40), SUM(ResolutionWidth + 41), SUM(ResolutionWidth + 42), SUM(ResolutionWidth + 43), SUM(ResolutionWidth + 44), SUM(ResolutionWidth + 45), SUM(ResolutionWidth + 46), SUM(ResolutionWidth + 47), SUM(ResolutionWidth + 48), SUM(ResolutionWidth + 49), SUM(ResolutionWidth + 50), SUM(ResolutionWidth + 51), SUM(ResolutionWidth + 52), SUM(ResolutionWidth + 53), SUM(ResolutionWidth + 54), SUM(ResolutionWidth + 55), SUM(ResolutionWidth + 56), SUM(ResolutionWidth + 57), SUM(ResolutionWidth + 58), SUM(ResolutionWidth + 59), SUM(ResolutionWidth + 60), SUM(ResolutionWidth + 61), SUM(ResolutionWidth + 62), SUM(ResolutionWidth + 63), SUM(ResolutionWidth + 64), SUM(ResolutionWidth + 65), SUM(ResolutionWidth + 66), SUM(ResolutionWidth + 67), SUM(ResolutionWidth + 68), SUM(ResolutionWidth + 69), SUM(ResolutionWidth + 70), SUM(ResolutionWidth + 71), SUM(ResolutionWidth + 72), SUM(ResolutionWidth + 73), SUM(ResolutionWidth + 74), SUM(ResolutionWidth + 75), SUM(ResolutionWidth + 76), SUM(ResolutionWidth + 77), SUM(ResolutionWidth + 78), SUM(ResolutionWidth + 79), SUM(ResolutionWidth + 80), SUM(ResolutionWidth + 81), SUM(ResolutionWidth + 82), SUM(ResolutionWidth + 83), SUM(ResolutionWidth + 84), SUM(ResolutionWidth + 85), SUM(ResolutionWidth + 86), SUM(ResolutionWidth + 87), SUM(ResolutionWidth + 88), SUM(ResolutionWidth + 89) FROM hits; |
数值计算 |
0.41s (×3.81) |
0.10s (×1.00) |
0.69s (×6.36) |
0.68s (×5.31) |
0.12s (×1.00) |
0.41s (×3.26) |
| SELECT SearchEngineID, ClientIP, COUNT(*) AS c, SUM(IsRefresh), AVG(ResolutionWidth) FROM hits WHERE SearchPhrase <> ‘’ GROUP BY SearchEngineID, ClientIP ORDER BY c DESC LIMIT 10; |
分桶 |
0.11s (×1.00) |
0.13s (×1.20) |
0.23s (×2.05) |
0.24s (×1.00) |
1.33s (×5.36) |
1.43s (×5.76) |
| SELECT WatchID, ClientIP, COUNT(*) AS c, SUM(IsRefresh), AVG(ResolutionWidth) FROM hits WHERE SearchPhrase <> ‘’ GROUP BY WatchID, ClientIP ORDER BY c DESC LIMIT 10; |
分桶 |
0.14s (×1.00) |
0.18s (×1.30) |
0.20s (×1.44) |
0.21s (×1.00) |
3.46s (×15.77) |
5.36s (×24.43) |
| SELECT WatchID, ClientIP, COUNT(*) AS c, SUM(IsRefresh), AVG(ResolutionWidth) FROM hits GROUP BY WatchID, ClientIP ORDER BY c DESC LIMIT 10; |
分桶 |
0.75s (×1.00) |
0.86s (×1.14) |
1.53s (×2.02) |
1.45s (×1.49) |
0.97s (×1.00) |
4.38s (×4.48) |
| SELECT URL, COUNT(*) AS c FROM hits GROUP BY URL ORDER BY c DESC LIMIT 10; |
分桶 |
0.67s (×1.00) |
0.96s (×1.44) |
1.67s (×2.49) |
1.84s (×1.93) |
0.95s (×1.00) |
9.13s (×9.52) |
| SELECT 1, URL, COUNT(*) AS c FROM hits GROUP BY 1, URL ORDER BY c DESC LIMIT 10; |
分桶 |
0.70s (×1.00) |
0.97s (×1.38) |
1.75s (×2.47) |
1.83s (×1.90) |
0.96s (×1.00) |
9.11s (×9.40) |
| SELECT ClientIP, ClientIP - 1, ClientIP - 2, ClientIP - 3, COUNT(*) AS c FROM hits GROUP BY ClientIP, ClientIP - 1, ClientIP - 2, ClientIP - 3 ORDER BY c DESC LIMIT 10; |
分桶 |
0.17s (×1.38) |
0.12s (×1.00) |
0.20s (×1.62) |
0.19s (×1.33) |
0.14s (×1.00) |
0.22s (×1.55) |
| SELECT URL, COUNT(*) AS PageViews FROM hits WHERE CounterID = 62 AND EventDate >= ‘2013-07-01’ AND EventDate <= ‘2013-07-31’ AND DontCountHits = 0 AND IsRefresh = 0 AND URL <> ‘’ GROUP BY URL ORDER BY PageViews DESC LIMIT 10; |
分桶 |
0.04s (×1.00) |
0.06s (×1.52) |
0.04s (×1.09) |
0.03s (×1.00) |
0.07s (×2.00) |
0.06s (×1.70) |
| SELECT Title, COUNT(*) AS PageViews FROM hits WHERE CounterID = 62 AND EventDate >= ‘2013-07-01’ AND EventDate <= ‘2013-07-31’ AND DontCountHits = 0 AND IsRefresh = 0 AND Title <> ‘’ GROUP BY Title ORDER BY PageViews DESC LIMIT 10; |
分桶 |
0.02s (×1.00) |
0.04s (×1.52) |
0.03s (×1.21) |
0.03s (×1.11) |
0.05s (×1.67) |
0.03s (×1.00) |
| SELECT URL, COUNT(*) AS PageViews FROM hits WHERE CounterID = 62 AND EventDate >= ‘2013-07-01’ AND EventDate <= ‘2013-07-31’ AND IsRefresh = 0 AND IsLink <> 0 AND IsDownload = 0 GROUP BY URL ORDER BY PageViews DESC LIMIT 10 OFFSET 1000; |
分桶 |
0.02s (×1.07) |
0.03s (×1.33) |
0.02s (×1.00) |
0.02s (×1.00) |
0.04s (×1.67) |
0.04s (×1.67) |
| SELECT TraficSourceID, SearchEngineID, AdvEngineID, CASE WHEN (SearchEngineID = 0 AND AdvEngineID = 0) THEN Referer ELSE ‘’ END AS Src, URL AS Dst, COUNT(*) AS PageViews FROM hits WHERE CounterID = 62 AND EventDate >= ‘2013-07-01’ AND EventDate <= ‘2013-07-31’ AND IsRefresh = 0 GROUP BY TraficSourceID, SearchEngineID, AdvEngineID, Src, Dst ORDER BY PageViews DESC LIMIT 10 OFFSET 1000; |
分桶 |
0.06s (×1.00) |
0.09s (×1.49) |
0.06s (×1.04) |
0.06s (×1.00) |
0.10s (×1.57) |
0.09s (×1.40) |
| SELECT URLHash, EventDate, COUNT(*) AS PageViews FROM hits WHERE CounterID = 62 AND EventDate >= ‘2013-07-01’ AND EventDate <= ‘2013-07-31’ AND IsRefresh = 0 AND TraficSourceID IN (-1, 6) AND RefererHash = 3594120000172545465 GROUP BY URLHash, EventDate ORDER BY PageViews DESC LIMIT 10 OFFSET 100; |
分桶 |
0.02s (×1.00) |
0.03s (×1.43) |
0.02s (×1.07) |
0.02s (×1.00) |
0.47s (×16.00) |
0.04s (×1.50) |
| SELECT WindowClientWidth, WindowClientHeight, COUNT(*) AS PageViews FROM hits WHERE CounterID = 62 AND EventDate >= ‘2013-07-01’ AND EventDate <= ‘2013-07-31’ AND IsRefresh = 0 AND DontCountHits = 0 AND URLHash = 2868770270353813622 GROUP BY WindowClientWidth, WindowClientHeight ORDER BY PageViews DESC LIMIT 10 OFFSET 10000; |
时间处理 |
0.02s (×1.00) |
0.03s (×1.48) |
0.02s (×1.11) |
0.02s (×1.00) |
0.25s (×8.67) |
0.02s (×1.13) |
| SELECT DATE_TRUNC(‘minute’, EventTime) AS M, COUNT(*) AS PageViews FROM hits WHERE CounterID = 62 AND EventDate >= ‘2013-07-14’ AND EventDate <= ‘2013-07-15’ AND IsRefresh = 0 AND DontCountHits = 0 GROUP BY DATE_TRUNC(‘minute’, EventTime) ORDER BY DATE_TRUNC(‘minute’, EventTime) LIMIT 10 OFFSET 1000; |
时间处理 |
0.01s (×1.00) |
0.03s (×1.60) |
0.02s (×1.20) |
0.02s (×1.07) |
0.04s (×1.79) |
0.02s (×1.00) |