参考资料Dataphin帮助文档 Dataphin和Dataworks的区别与各自定位?
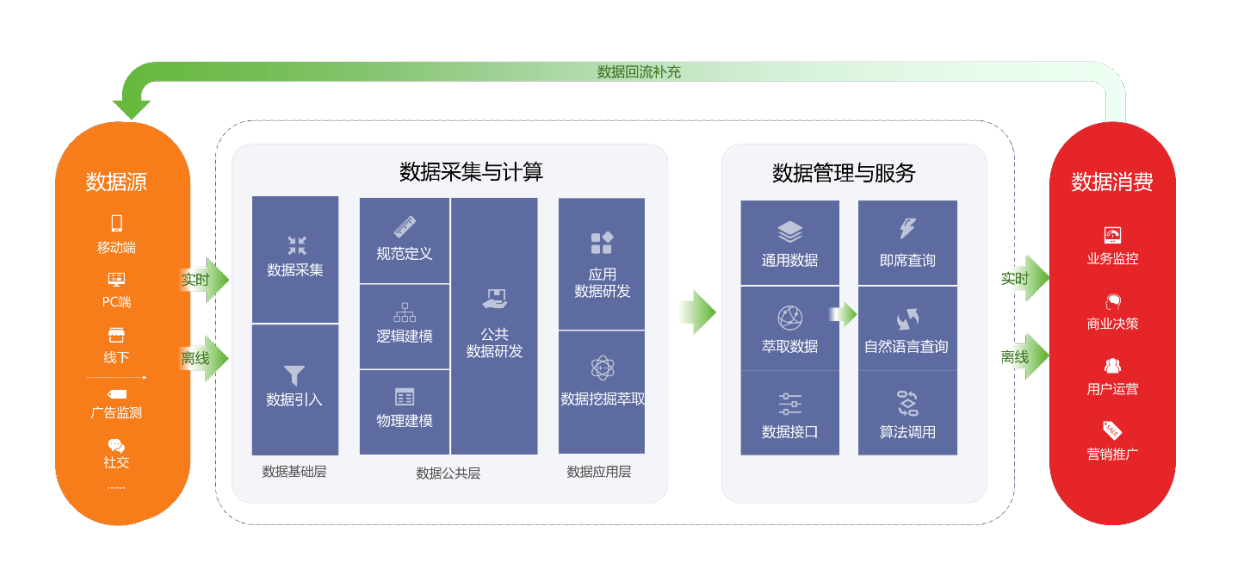
Dataphin简介 Dataphin是阿里巴巴集团OneData数据治理方法论内部实践的云化输出,一站式提供数据采、建、管、用全生命周期的大数据能力,以助力企业显著提升数据治理水平,构建质量可靠、消费便捷、生产安全经济的企业级数据中台。遵循阿里巴巴集团多年实战沉淀的大数据建设OneData体系(OneModel、OneID、OneService),集产品、技术、方法论于一体,一站式地为您提供集数据引入、规范定义、数据建模研发、数据萃取、数据资产管理、数据服务等的全链路智能数据构建及管理服务。
Dataphin的主要功能模块包括:
平台管理:平台管理是Dataphin的基础功能,主要包含全局化功能设置和首页引导。
全局设计:基于业务全局,从顶层自下规划设计业务数据总线,包括:划分命名空间 、定义主题域及相关名词 、划分管理单元(即项目) 、定义数据源 及计算引擎源 。
数据引入:数据引入基于全局设计定义的项目空间与物理数据源,将各业务系统、各类型的数据抽取加载至目标数据库。
规范定义:基于全局设计定义的业务总线、数据引入构建的基础数据中心,根据业务数据需求,结构化地定义数据元素(例如维度、统计指标),保障数据无二义性地标准化、规范化生产。
建模研发:基于规范定义的数据元素,设计与构建可视化的数据模型。
编码研发:基于通用的代码编辑页面,灵活地进行个性化的数据编码研发,完成任务发布。
资源及函数管理:支持管理各种资源包,支持查找与使用内置的系统函数,支持用户自定义函数。
数据萃取:基于Dataphin数据建模研发沉淀的数据,萃取提供以目标对象为中心的数据打通和深度挖掘,并生成代码与调度任务,完成实体对象识别、连接及标签生产,可快速应用于各类业务。
调度运维:对建模研发、编码研发生成的代码任务进行基于策略的调度与运维,确保所有任务正常有序地运行。
即席查询:支持用户通过自定义SQL等方式,查询数据资产中的数据。
数据服务:数据服务为您提供高效便捷的主题式查询功能及有效的全链路企业内API生命周期托管
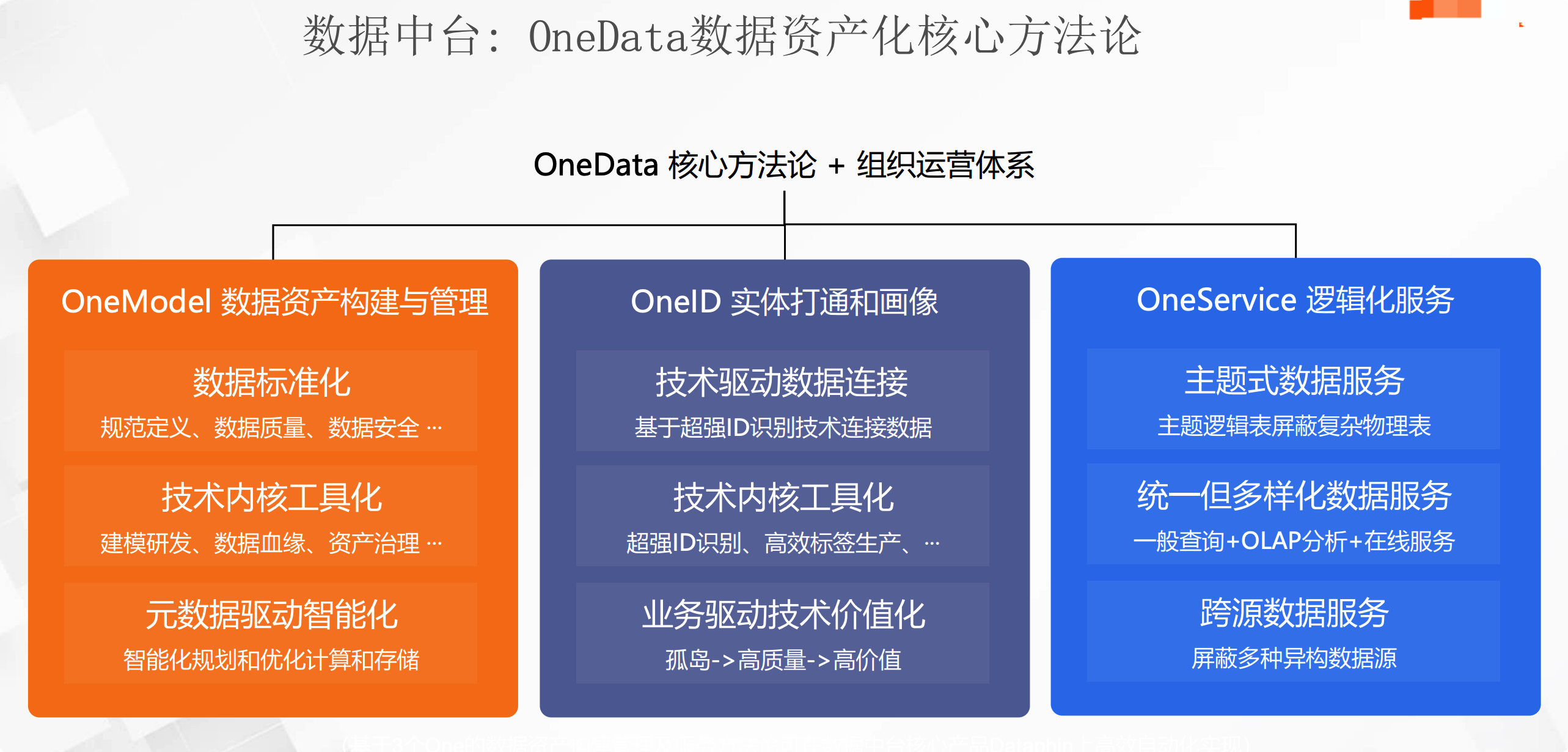
阿里OneData思想下的数仓结构 阿里云OneData数据中台解决方案基于大数据存储和计算平台为载体,以OneModel统一数据构建及管理方法论为主干,OneID核心商业要素资产化为核心,实现全域链接、标签萃取、立体画像,以数据资产管理为皮,数据应用服务为枝叶的松耦性整体解决方案。其数据服务理念根植于心,强调业务模式,在推进数字化转型中实现价值。
OneModel 统一模型构建与管理。通过全域数据集成、数据分层架构、业务视角标准规范定义数据和处理数据,致力于统一数据口径、消除指标二义性;
OneID 即建立业务实体要素资产化为核心,实现全域链接、标签萃取、立体画像,其数据服务理念根植于心,强调业务模式。核心商业要素资产化。以业务和自然对象为基础,以标签数据为核心,能够实现全域实体识别与连接,数据价值深度萃取,助力企业构建标签体系、完成核心商业要素资产化;
OneService 即数据被整合和计算好之后,需要提供给产品和应用进行数据消费,为了更好的性能和体验,需要构建数据服务层,通过统一的接口服务化方式对外提供数据服务。统一的主题式服务。以业务便捷消费数据为目标,建立主题式的数据服务单元,面向应用快速构建 API 以提供服务,建立起统一的数据服务中心。
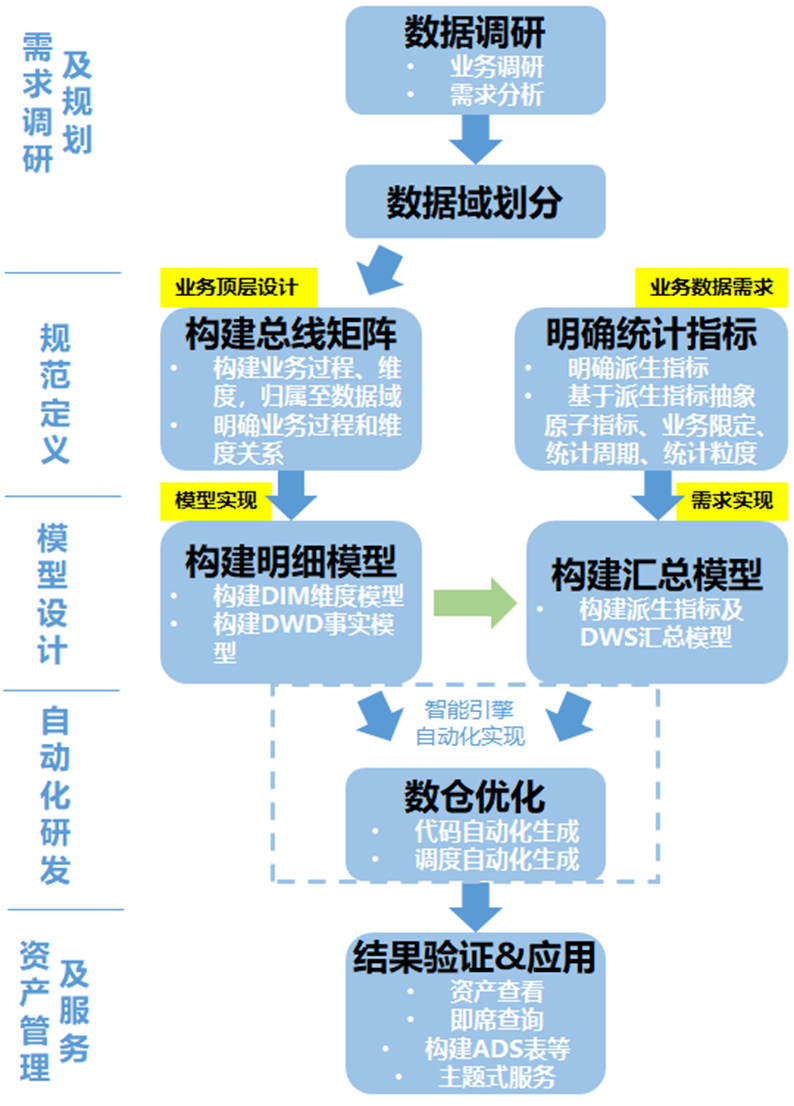
数仓构建流程
数仓分层
维度设计原则
尽可能生成丰富的 维度属性。例如电商公司的商品维度可能有近百个维度属性,为下游的数据统计、分析、探查提供了良好的基础。
尽可能多的给出包含一些富有意义的文字性描述 。属性不应该是编码,而应该是真正的文字。在阿里巴巴维度建模中,通常是编码和文字同时存在,例如商品维度中的商品ID和商品标题、类目ID和类目名称等。ID
区分数值型属性和事实。数值型字段是作为事实还是维度属性,可以根据字段的常用用途区分。例如,若用于查询约束条件或分组统计,则是作为维度属性;若用于参与度量的计算,则是作为事实。 尽量沉淀出通用的维度属性。
通过逻辑处理得到维度属性。
通过多表关联得到维度属性。
通过单表的不同字段混合处理得到维度属性。
通过对单表的某个字段进行解析得到维度属性。
明细数据层 事实表(事实模型,又称事实逻辑表)作为数据仓库维度建模的核心,紧紧围绕着业务过程进行设计。业务过程是通过事实表的度量、引用的维度与业务过程有关属性的方式获取。
尽可能包含所有与业务过程相关的事实。
只选择与业务过程相关的事实。
在选择维度和事实之前,必须先声明粒度。
在同一个事实表中,不能包含多种不同粒度的事实。
事实的单位要保持一致。
汇总数据层 汇总数据层以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求构建公共粒度的汇总表。汇总数据层的一个表通常会对应一个统计粒度(维度或维度组合)及该粒度下若干派生指标。
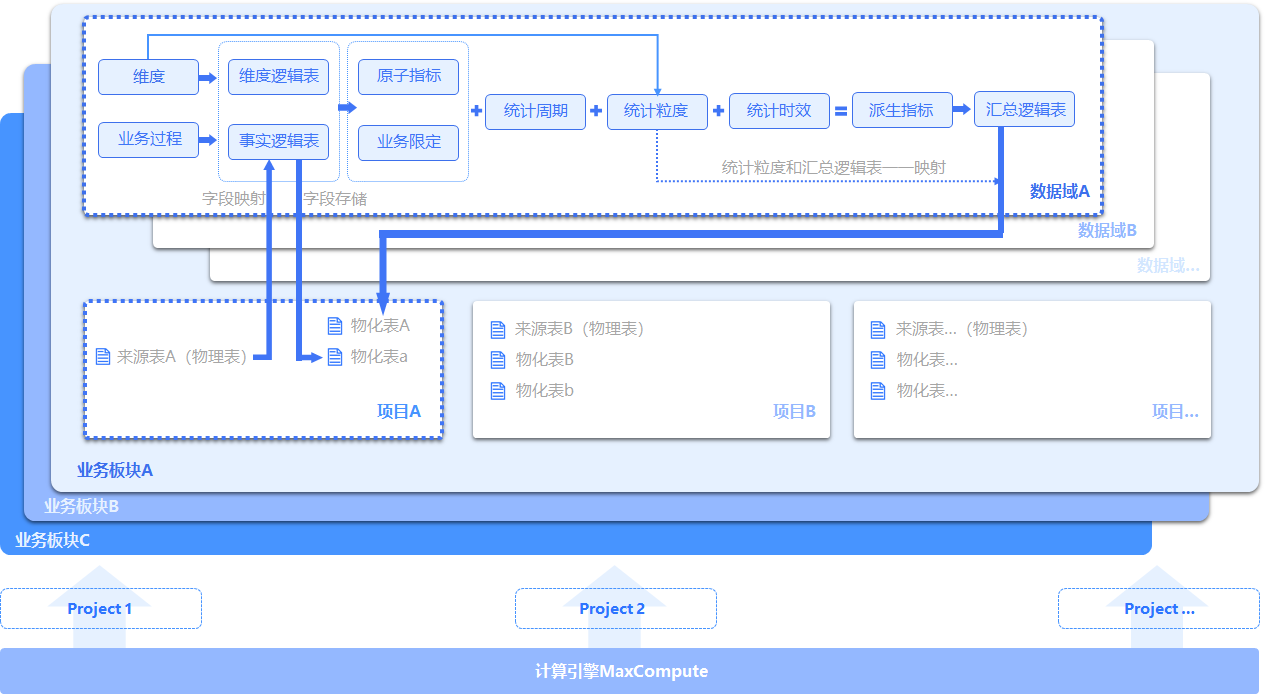
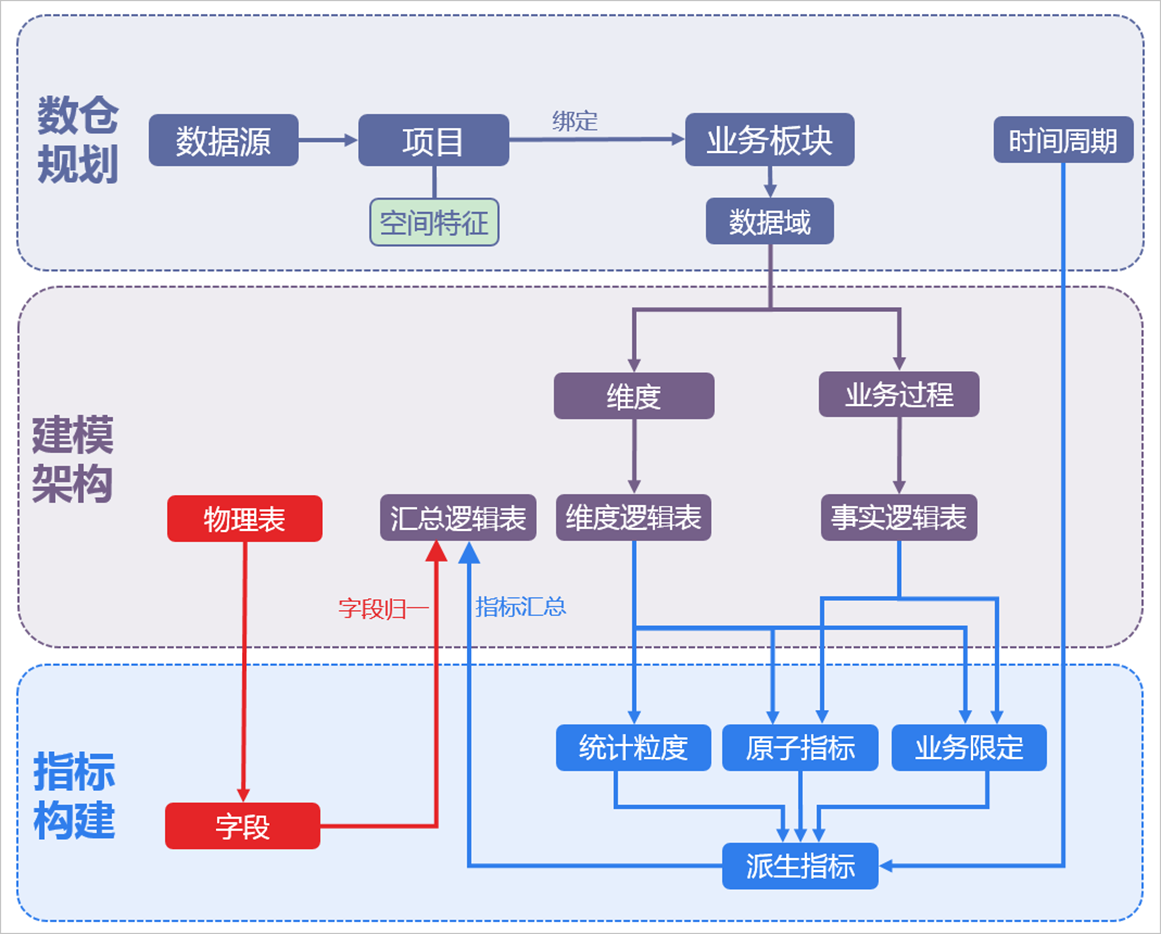
Dataphin模型结构 Dataphin核心概念的逻辑结构
业务模型层 和计算引擎层 :业务模型层从业务视角对数据进行重新定义组织,分类打标;计算引擎层承载数据的实际计算与存储。业务模型层按照不同的业务形态,划分出业务板块,一种业务形态对应一个业务板块。
同一种业务形态(业务板块)内,根据实际业务情况,将业务实体(维度和业务过程)划分到不同的数据域。
基于维度和业务过程创建明细逻辑表 (包括维度逻辑表和事实逻辑表),及定义指标 (包括原子指标、业务限定、统计周期、统计粒度、统计时效、派生指标)。
说明
在Dataphin 3.3版本,维度更名为业务对象,业务过程更名为业务活动,数据域更名为主题域,业务板块更名为数据板块。
核心概念的详细内容
核心概念
简要含义
数据板块
数据板块定义了数据仓库的多种命名空间,是一种系统级的概念对象。当数据的业务含义存在较大差异时,您可以创建不同的数据板块,让各成员独立管理不同的业务,后续数据仓库的建设将按照数据板块进行划分。一个数据板块代表一种业务含义。 例如,零售数据板块、文娱数据板块。数据板块内的数据是完整的 ,即一个板块内可以独立完成从数据采集到最后的数据加工。
主题域
数据域即主题域,是对某个主题分析后确定的主题边界。例如,商品域、交易域、会员域等。一个主题域代表一种业务含义 。例如,商品域、交易域。
业务对象
业务对象即参与业务的主体 和客体 ,通常情况下业务对象是实际存在、不因事件发生而存在的对象。例如客户、员工、产品等具体的业务对象;地域、组织关系和产品类目等抽象的业务对象。
业务活动
业务过程即企业的业务活动事件,通常为不可拆分的事件 ,是一个或者多个业务对象在某个时间或时间段,为了达成某种目的所进行的活动或者是某种活动的结果。
项目
项目是一种物理空间上的划分,便于用户在数据中台建设过程中对物理资源及开发人员进行隔离化管理。一个数据板块可以包含多个项目,Dataphin成员可以加入到多个不同的项目。项目与底层计算引擎的物理空间(例如,MaxCompute项目,Hive Database)一一对映。根据数据板块内数据的加工的程度,会将数据划分为三层,每一层一般对应独立的项目:
维度
人们观察事物的角度,是指一种视角,是确定事物的多方位、多角度、多层次的条件和概念。group by后的字段。
维度逻辑表
丰富维度的属性信息形成的逻辑表。通过维度逻辑表可以设计及加工处理公共对象明细数据,以便提取业务中对象的明细数据。
事实逻辑表
用于描述业务过程的详细信息。通过创建事实逻辑表可以设计及加工处理公共事务明细数据,以便提取业务中事务的明细数据。
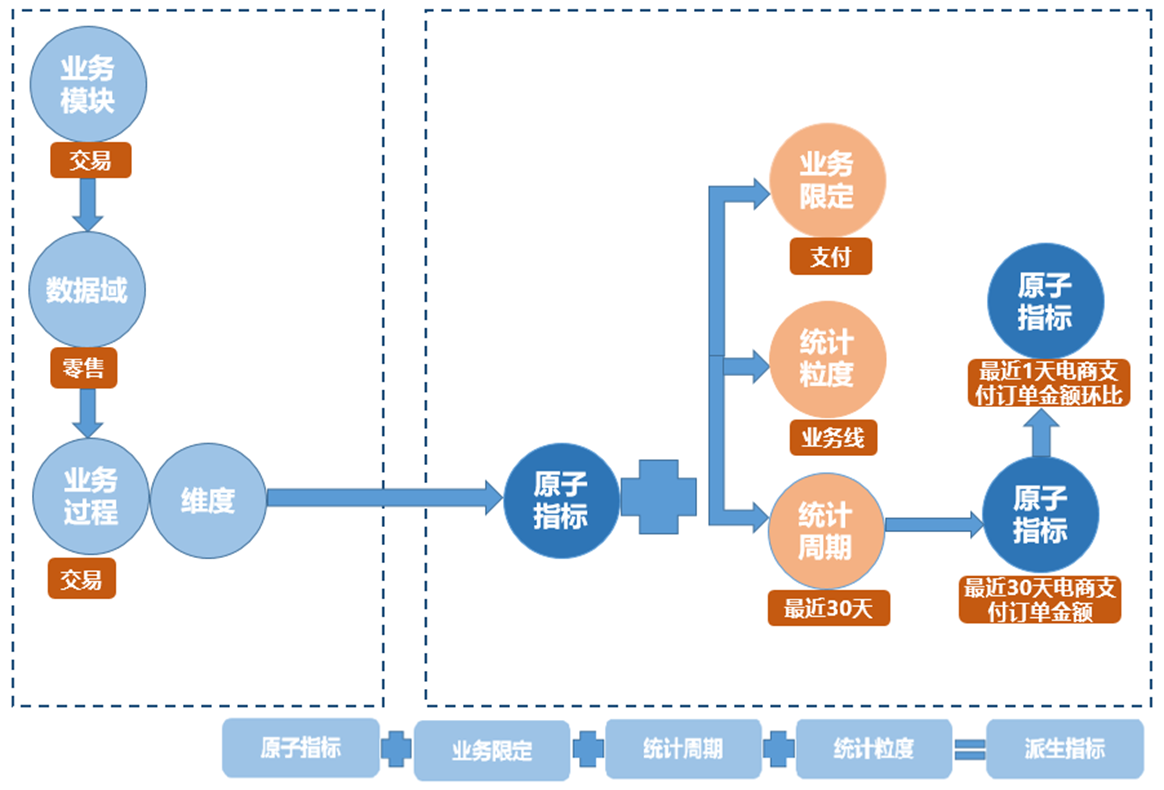
原子指标
对指标统计口径、具体算法的抽象。 例如,支付金额。
衍生原子指标
基于原子指标做二次多元计算的表达式。例如原子指标A和B,可以定义衍生原子指标C=A/B。
业务限定
统计的业务范围,用于筛选出符合业务规则的记录(类似于SQL中Where后的条件,不包括时间区间)。
统计周期
定义派生指标的来源数据的时间跨度。例如最近1天、最近30天等(类似于SQL中Where后的时间条件)。
统计粒度
统计分析的对象或视角,用于圈定数据的统计范围,您也可以理解为聚合运算时的分组条件(类似于SQL中Group By的对象)。
统计时效
派生指标的计算频次,即派生指标产出的时间间隔。
派生指标
即基于原子指标、时间周期和维度,圈定业务统计范围并分析获取业务统计指标的数值。派生指标=原子指标+业务限定+统计周期+维度或维度的组合(统计粒度)。
汇总逻辑表
派生指标归属的表就是汇总逻辑表。
物理表
计算引擎中的表,即通过DDL创建的表。
物化表
存储逻辑表真实数据的物理表。维度辑逻表、事实逻辑表或汇总逻辑表是Dataphin内一种表的定义,类似传统数据库里的视图。真实的数据是存储在计算引擎的物理表中,这些物理表就是逻辑表的物化表 ,一个逻辑表可能有多个物化表(只有有主键的逻辑表才能有多个物化表,每个物化表都包含主键字段)。
基本概念之间的关系
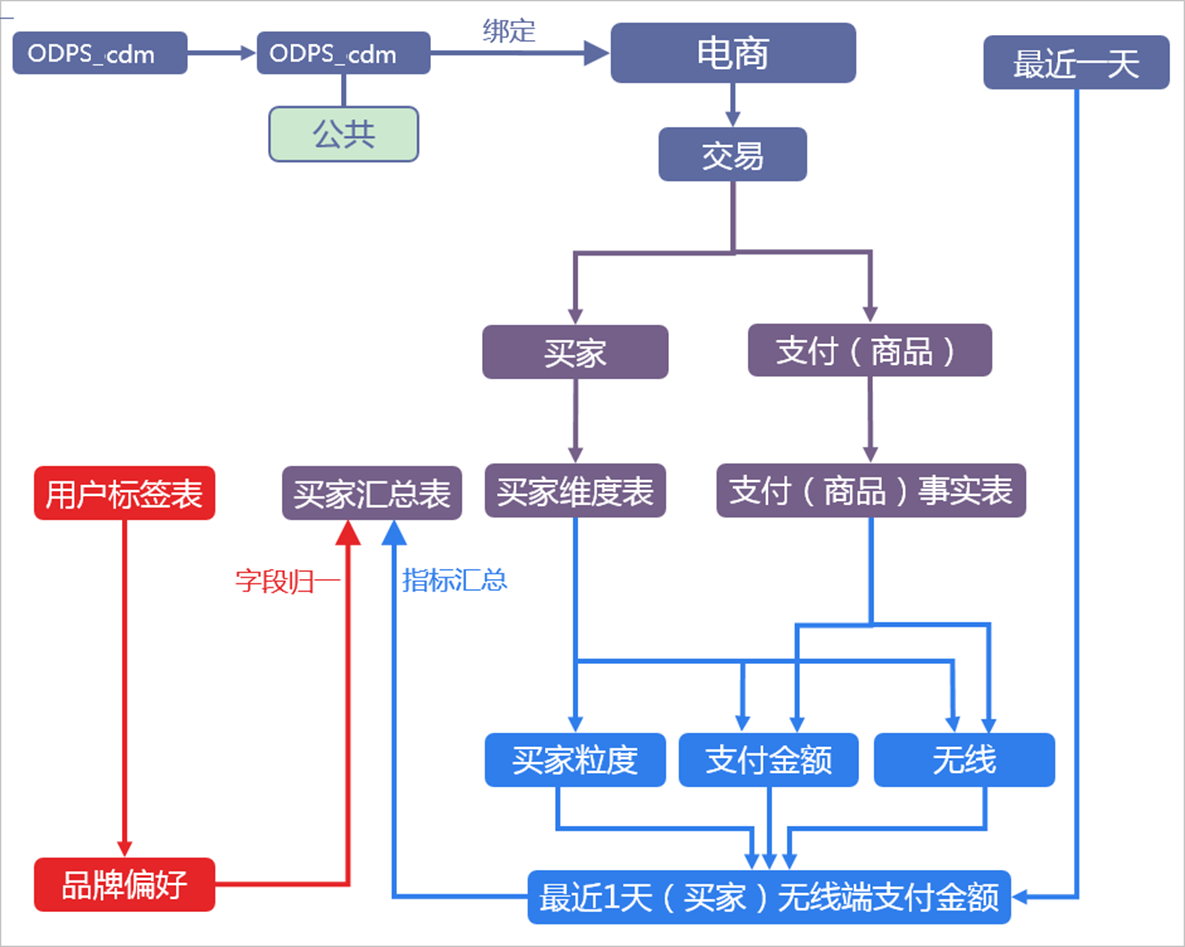
Dataphin案例介绍 以某公司的零售事业群为例
规划数仓
规划业务板块。
事业部之间不共享资源,人员独立、办公场地独立等。即从Dataphin的实施角度来看,事业部之间不存在共同的业务对象(业务参与人或物)。
事业部之间不存在业务流程的流转。零售事业群的某个作业流程(如采购、销售)与金融事业部完全无关。
零售板块
金融板块
地产板块
规划项目。
ODS层项目(dummy_retail_ods_dev和dummy_retail_ods),用于存放从各个业务系统每天同步过来的原始数据.
CDM层项目(dummy_retail_cdm_dev和dummy_retail_cdm), 用于存放企业内通用,且经常被很多业务场景使用的数据。
ADS层项目(dummy_retail_ads_dev和dummy_retail_ads),面向业务场景。
划分数据域。
会员(消费者)域
商品域
门店域
交易域
供应链域
履约域
营销域
服务域
流量域
公共域
确定维度与业务过程。
列举出业务活动,下表仅列举了部分业务活动。
数据域
业务活动
交易域
订单、支付
供应链域
采购、运输、仓储(入库、上架、拣选、出库、盘点等)
履约域
接单、配送
拆分上述步骤中每个业务活动的参与对象和业务活动中的关键节点,下表仅列举了部分参与对象和关键节点。
数据域
业务活动
参与对象
关键节点
交易域
订单
消费者、门店、商品
下单、支付、关单 重要 线下订单下单、支付、关单在POS支付那一刻就全部完成。
交易域
支付
消费者
创建(支付单)、支付、关单
供应链域
采购
供应商、商品、仓库
确认采购单、预付、发货、收货、付尾款、关单
供应链域
运输、调拨
仓库、商品、承运商、门店
确认调拨单、发运、收货、关单
履约域
配送
仓库、商品、消费者
发货、收货、关单
确定维度及其所在的数据域。
有公共性的对象(即参与了多个数据域业务活动的对象),通常都设置了独立的数据域,如消费者域。
只参与某一个数据域的业务活动的对象归属在所在数据域。
维度的属性延展出来的维度,与本维度在同一个数据域。
基于以上原则,确定的维度及维度归属的数据域如下表所示,下表仅列举了部分维度及归属数据域。
数据域
维度
消费者域
消费者、性别、年龄层、职业等
商品域
商品、类目
门店域
门店
供应链域
供应商、仓库、承运商
确定业务过程
数据域
业务过程
交易域
下单、支付、关单;创建(支付单)、支付、支付关单
供应链域
确认采购单、预付、发货、收货、付尾款、采购关单确认调拨单、发运、收货、调拨关单
履约域
发货、收货、关单
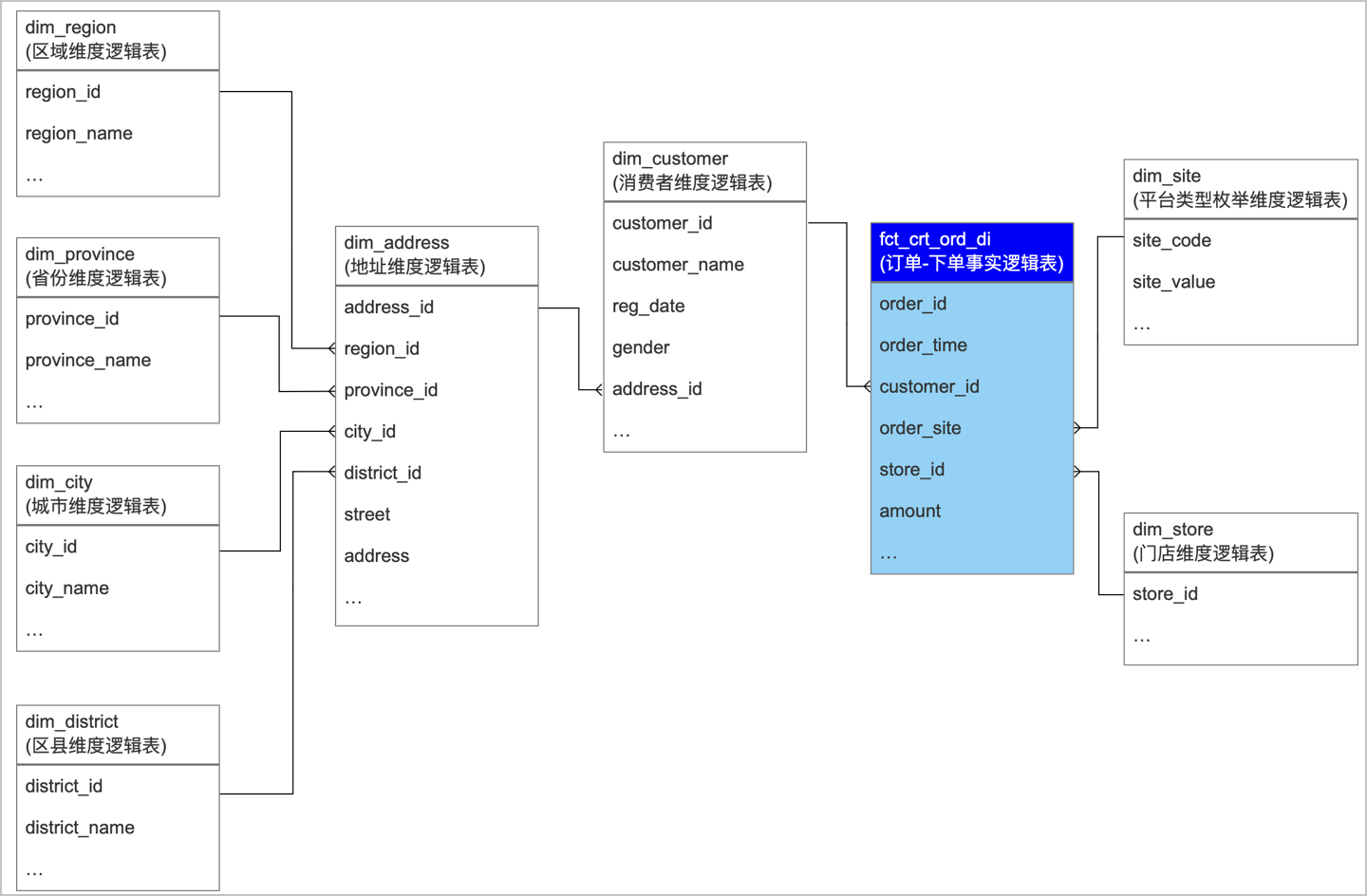
配置维度逻辑表
属性字段
说明
来源字段
关联维度
customer_id
客户ID
dummy_retail_ods.s_customer.id
无
customer_name
消费者名称
dummy_retail_ods.s_customer.name
无
reg_date
注册日期
dummy_retail_ods.s_customer.reg_date
无
gender
性别
dummy_retail_ods.s_customer.gender
性别
address_id
消费者注册地址
dummy_retail_ods.s_customer.address_id
地址
地址是一个公共域维度,其维度逻辑表为下表所示,仅列举了部分属性字段。
属性字段
说明
来源字段
关联维度
address_id
内部ID
dummy_retail_ods.s_address.id
无
region_id
区域ID
dummy_retail_ods.s_address.region_id
区域
province_id
省份ID
dummy_retail_ods.s_address.prov_id
省
city_id
城市ID
dummy_retail_ods.s_address.city_id
城市
district_id
区县ID
dummy_retail_ods.s_address.district_id
区县
street
街道
dummy_retail_ods.s_address.street
无
address_detail
详细地址
dummy_retail_ods.s_address.addr
无
配置事实逻辑表
属性字段
说明
来源字段
关联维度
order_id
订单ID
dummy_retail_ods.s_order.id
无
order_time
下单时间
dummy_retail_ods.s_order.gmt_create
无
customer_id
消费者(买家)ID
dummy_retail_ods.s_order.buyer_id
消费者
order_site
订单来源平台
dummy_retail_ods.s_order.order_source
平台类型(枚举)
store_id
门店ID
dummy_retail_ods.s_order.store_id
门店
amount
订单金额
dummy_retail_ods.s_order.amount
无
该事实逻辑表关联了消费者维度,消费者维度又关联了地址,地址关联了地域相关的多个维度。
定义指标 下文以消费者运营团队统计 最近30天内每个消费者线上下单金额 为例,为您介绍如何定义其中的指标。
按照传统SQL研发方式,您可以使用以下代码,统计 最近30天内每个消费者线上下单金额 。
1 2 3 4 5 6 7 8 select customer_id ,sum (amount) as order_amt_30d from fct_crt_ord_di where ds >= '20210901' and ds <= '20210930' and order_site = 1 group by customer_id
根据上述代码为您介绍如何定义统计周期、统计粒度、统计时效、原子指标、业务限定和派生指标:
统计周期
统计粒度
统计时效
原子指标sum(amount)。下单金额是最基础、且不可拆分的事件。从SQL角度来看,下单金额sum(amount)是一个简单的聚合表达式。
业务限定order_site=1。
派生指标
Dataworks与Dataphin区别 区别1:产品功能不同
区别2:产品定位不同
区别3:实时计算能力
【总结】