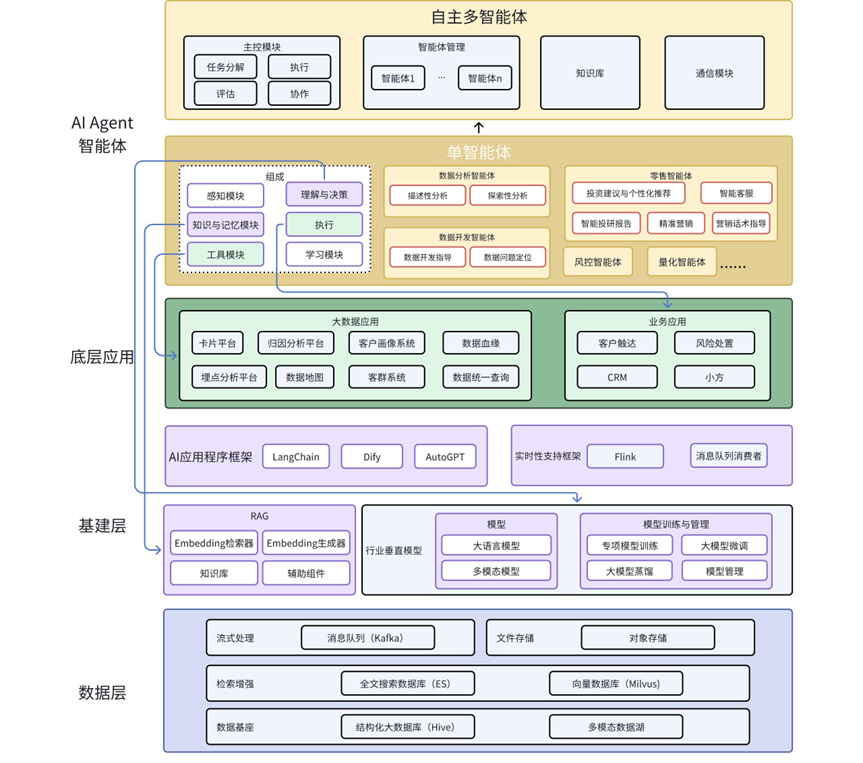
架构图
背景
大数据与AI的关系
大数据让人工智能变得更加智能,
人工智能让大数据变得更有价值。
- 大数据为AI提供“燃料”
- 训练基础:深度学习模型依赖大量数据训练,数据量直接影响模型性能。
- 多样性增强:结构化与非结构化数据的融合(如文本、图像、传感器数据)帮助AI捕捉复杂模式。
- 数据质量提升:清洗与标注技术优化减少AI模型的“垃圾输入”问题。
- AI为大数据提炼价值
- 智能分析:AI通过深度学习从数据中自动发现非线性关系。
- 实时决策:结合流数据处理,AI实现秒级甚至毫秒级响应。
- 数据生成与增强:生成式AI可合成虚拟数据,缓解数据稀缺问题。
AI数字化转型路线
- 基础设施云化与数据资产化
核心目标:构建数字化底座,让数据成为核心资产- 云原生架构:采用混合云、私有云,提升弹性算力(如中信证券与阿里云合作搭建金融云)。
- 数据中台:整合交易、客户、市场数据,形成统一数据资产(如华泰证券的“数据工厂”)。
- AI 算力储备:部署 GPU/TPU 集群,支持大模型训练(如国泰君安自建 AI 算力中心)。
- 业务智能化与自动化
核心目标:用 AI 重构核心业务流程,提升效率与体验- 智能投研:AI 辅助研报生成、舆情分析(如中金公司“AI 策略报告”)。
- 智能投顾:个性化资产配置(如广发证券“贝塔牛”)。
- 智能风控:实时监测异常交易(如东方证券 AI 风控系统)。
- RPA+AI:自动化运营(如东吴证券合同审核效率提升 80%)。
- 服务场景化与生态化
核心目标:从“单一金融产品”转向“场景化服务生态”- 嵌入场景:与互联网平台合作(如华泰证券与同花顺、雪球合作)。
- 开放 API:让客户、第三方开发者接入(如中信证券 CAP 开放平台)。
- 数字员工:AI 客服、AI 投顾(如中信证券“数字人助理”)。
层级与组件介绍
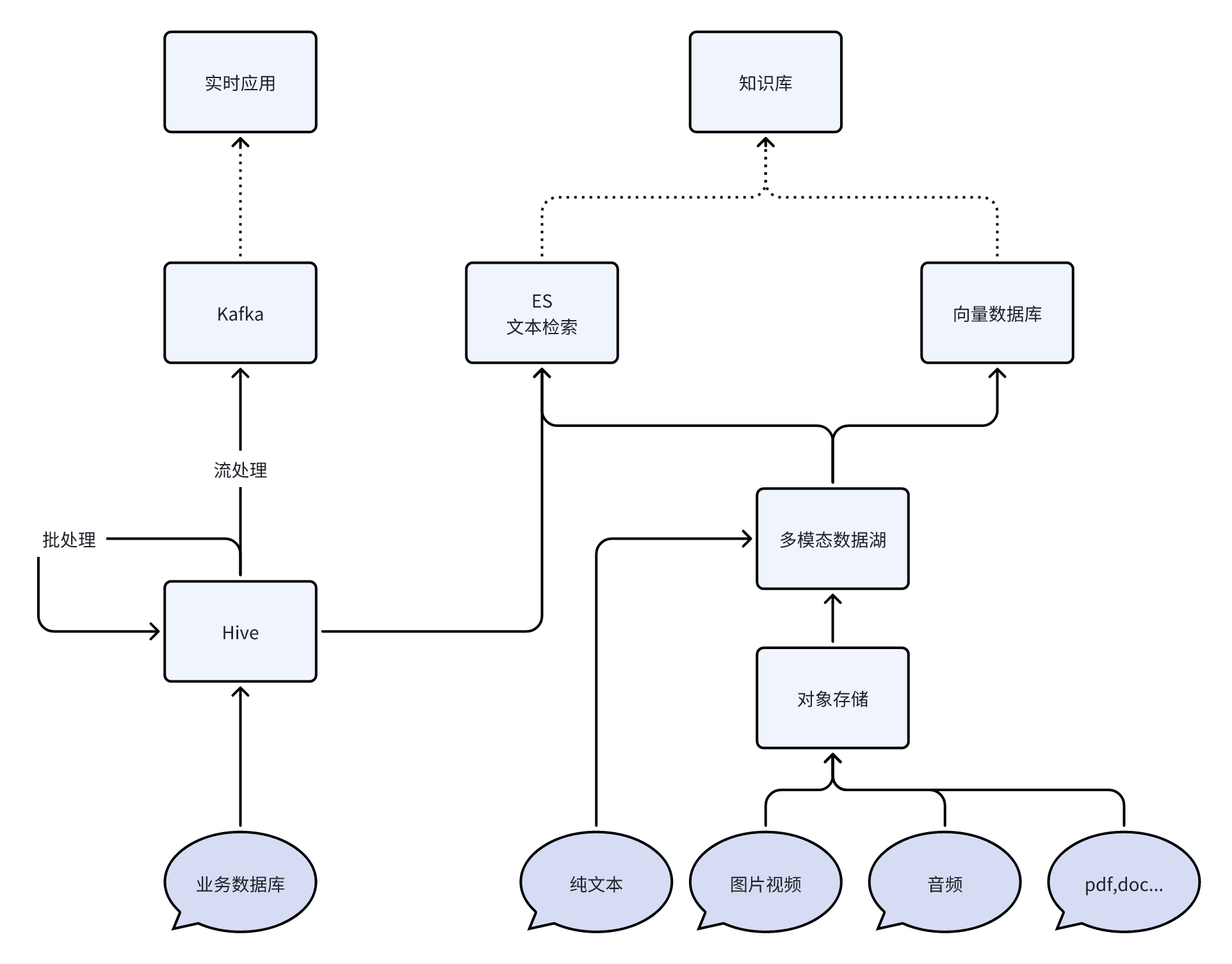
数据层
- 核心作用:为上层提供多模态数据支持,以及各种形态数据的存储、管理、访问。
- 关键组件:
- 流式数据载体:Kafka(消息队列)
- 结构化数据:Hive(批处理结果)。
- 非结构化数据:多模态数据湖(图像视频/音频/文本/文件等)。
- 搜索工具:ES(全文检索),Milvus(向量管理与检索)。
- 典型应用:模型训练的数据来源、智能体的知识库基础。
多模态数据湖
以Deep Lake为例,其核心功能包括:
- 多模态数据支持:
支持图像、视频、音频、文本、PDF、DICOM(医学影像)等数据类型,统一存储为张量格式(如 NumPy 数组),兼容 PyTorch/TensorFlow 等框架。 - 版本控制:
类似 Git 的分支管理(commit/checkout)、标签功能和合并操作,便于团队协作和实验回溯。 - 高效查询与检索:
- TQL 查询引擎:支持语义搜索和过滤(如 ds.filter(lambda x: x.label == ‘cat’))。
- 向量搜索:集成 LangChain/LlamaIndex,适用于 LLM 应用的嵌入检索。
- 性能优化:
- 流式加载:惰性加载数据,减少训练等待时间。
- 原生压缩:图像/视频保持压缩格式,节省存储空间。
向量数据库
以Milvus(Faiss基础上开发)为例,其搜索功能包括:
KNN 搜索:查找最接近查询向量的前 K 个向量。
过滤搜索:在指定的过滤条件下执行 ANN 搜索。
范围搜索:查找查询向量指定半径范围内的向量。
混合搜索:基于多个向量场进行 ANN 搜索。
全文搜索:基于 BM25 的全文搜索。
Rerankers:根据附加标准或辅助算法调整搜索结果顺序,完善初始 ANN 搜索结果。
获取:根据主键检索数据。
查询:使用特定表达式检索数据。
整体数据流向
基建层
- 核心能力:行业垂直模型开发与管理、知识库、AI应用程序框架、实时应用框架。
- 关键模块:
- 模型相关:大语言模型、Embedding生成/检索、模型蒸馏(轻量化)。
- 知识管理:检索增强(RAG)、知识库构建。
- 应用程序框架:LangChain(链式应用框架),Dify(链式应用框架的低代码平台),AutoGPT(自主任务执行),MetaGPT(多智能体协作框架)
- 目标:支持从通用大模型到垂直领域微调的完整流程。
行业垂直模型
本人对模型了解不多,只给出一些可能方向
- 金融大语言模型(LLM)
- 微调方式:
- 指令微调(如“生成某股票的深度分析”)
- RLHF(人类反馈强化学习)确保合规性(如避免误导性投资建议)
- 精调:数百条高质量样本,强化某些注意力头
- 核心能力:
- 金融文本理解(如财报摘要、行业趋势分析)
- 投资逻辑推理(如“为什么某股票近期下跌?”)
- 合规审核(如识别潜在违规表述)
- 微调方式:
- 语音模型(ASR+TTS+NLP)
- 语音识别(ASR):高精度金融术语识别(如“市盈率”“量化宽松”)。
- 语音合成(TTS):自然语音播报(如实时行情播报、AI投顾交互)。
- 语音NLP:
- 客户语音查询理解(如“帮我查一下宁德时代的研报”)
- 情绪分析(如识别客户投诉或投资焦虑)
- 多模态模型(视觉+文本)
- 图表理解:解析K线图、财报图表、行业趋势图。
- 文档OCR:扫描合同、研报、公告,提取关键信息。
- 视频分析:解读财经新闻视频、路演直播内容。
RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是AI领域的一项前沿技术,旨在通过结合外部知识检索与生成式模型的能力,提升大型语言模型(LLM)在知识密集型任务中的准确性和时效性。
RAG通过以下几个关键阶段工作:
- 数据准备:
- 数据提取
- 数据加载:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式。
- 数据处理:包括数据过滤、压缩、格式化等。
- 元数据获取:提取数据中关键信息,例如文件名、Title、时间等 。
- 文本分割(Chunking):
文本分割主要考虑两个因素:1)embedding模型的Tokens限制情况;2)语义完整性对整体的检索效果的影响。一些常见的文本分割方式如下:- 句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
- 固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
- 向量化(embedding):
向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果。目前常见的embedding模型如表中所示,这些embedding模型基本能满足大部分需求,但对于特殊场景(例如涉及一些罕见专有词或字等)或者想进一步优化效果,则可以选择开源Embedding模型微调或直接训练适合自己场景的Embedding模型。
- 数据提取
- 检索阶段:
- 文本:
- 利用传统信息检索模型(如BM25)从外部知识库(全文搜索数据库)中检索与用户查询相关的文档片段。
- 使用词向量,与传统信息检索模型类似
- 利用上下文相关模型(如BERT)生成句向量进行向量检索
- 多媒体与文件:用户提问时,问题被实时向量化,通过近似最近邻(ANN)算法(如HNSW)快速匹配最相关的知识片段
- 文本:
- 生成阶段:将检索到的上下文输入LLM,生成基于实际知识的回答,而非仅依赖模型预训练的参数化知识。
检索阶段的优化途径:
- 查询转换。使用 LLM 作为推理引擎来修改用户输入以提高检索质量。
- 分层索引。摘要和正文分开索引,先快速检索摘要,再检索正文
- 假设性问题和 HyDE。LLM 为每个块生成一个问题,并将这些问题嵌入到向量中,在运行时对这个问题向量的索引执行查询搜索(将块向量替换为索引中的问题向量),然后在检索后路由到原始文本块并将它们作为 LLM 获取答案的上下文发送。这种方法提高了搜索质量,因为与实际块相比,查询和假设问题之间的语义相似性更高。还有一种叫做 HyDE 的反向逻辑方法——你要求 LLM 在给定查询的情况下生成一个假设的响应,然后将其向量与查询向量一起使用来提高搜索质量。
- 检索结果增强。两种选择:一种是将检索出来的较小的文本块的上下文一并返回;另一种是如果检索出的多个小块归属于同一个大块,则将这个大块整个返回
- 融合检索或混合搜索:同时使用传统全文搜索和向量检索召回结果,通过Reciprocal Rank Fusion 算法进行结果的重排序并且返回。
- 重排(reranking)和过滤(filtering)根据相似性分数、关键字、元数据过滤掉结果,或使用其他模型(如 LLM)、sentence-transformer 交叉编码器,Cohere 重新排名接口或者基于元数据重排它们。
常见的Embedding生成器
| 模型名称 | 类型 | 支持语言 | 最大Token | 特点 | 适用场景 |
|---|---|---|---|---|---|
| OpenAI text-embedding-3-small | 文本 | 多语言 | 8192 | 轻量级,检索任务平均分61.0,适合快速验证 | 通用文本检索、RAG基础版 |
| OpenAI text-embedding-3-large | 文本 | 多语言 | 8192 | 高精度,检索任务平均分64.6,延迟较高 | 高精度语义匹配、复杂问答 |
| BGE-M3 | 文本 | 194种 | 8192 | 多语言榜首,支持密集/稀疏/多向量检索,长文本处理强 | 多语言知识库、长文档解析 |
| Sentence-BERT | 文本 | 多语言 | 512 | 句子级嵌入,语义相似度计算精准,开源易部署 | 短文本匹配、推荐系统 |
| ResNet50 | 图像 | - | - | 图像特征提取老将,适合以图搜图 | 电商图片检索、视频帧分析 |
| PANNs | 音频 | - | - | 预训练音频模型,支持音乐分类、语音检索 | 音频内容识别、智能客服录音分析 |
| CLIP/SigLIP | 多模态 | 多语言 | 77(文本) | 文图互搜,SigLIP优化了zero-shot效果,适合跨模态搜索 | 广告创意检索、多模态推荐 |
| Word2Vec | 文本 | 单语言 | - | 经典词向量,训练成本低,但无法处理一词多义 | 简单语义分析、教学演示 |
词向量转句向量方法:
- 短文本:优先尝试BERT的[CLS]向量或SIF加权
- 长文档:使用LSTM分层编码或分段+池化
- 资源受限:TF-IDF加权平均+PCA降维
* 领域适配:在目标数据上微调Sentence-BERT
应用程序框架对比
| 维度 | LangChain | Dify | AutoGPT | MetaGPT |
|---|---|---|---|---|
| 产品形态 | Python/JS代码库(需编程) | 可视化低代码平台(BaaS+LLMOps) | 自主任务执行的AI | Agent框架 |
| 抽象层级 | 底层模块化工具链(高灵活性) | 高度封装(开箱即用) | 任务自动化引擎(目标驱动) | 高层工作流编排(角色分工/SOP标准化) |
| 目标用户 | 开发者/技术团队(需编程能力) | 全团队协作(非技术成员可参与) | 个人/企业(自动化需求) | 企业开发者/AI工程团队(需复杂任务自动化) |
| 模型支持 | 需手动适配接口(如HuggingFace) | 一键切换数百个模型(统一API) | 默认依赖GPT系列,社区扩展有限 | 依赖大模型API(如GPT-4生成代码/规划) |
| 扩展性 | 高(可集成任意API/数据库) | 依赖插件市场,企业功能完善 | 任务分解能力强,但生态较封闭 | 模块化设计(可自定义角色/工具链) |
| 核心优势 | 灵活性高,适合复杂系统 | 开发效率极快,企业级支持完善 | 自动化任务执行 | 标准化协作流程(显式分解复杂任务) |
| 主要短板 | 学习曲线陡峭,维护成本高 | 定制能力有限 | 资源消耗大,稳定性待提升 | 成本敏感(多Agent调用放大API开销) |
实时性支持
实时性支持此处列举得比较简单,但其实施通常是对整个链路的改造,包括以下几个方面:
1. AI agent感知层的实时触发
- 事件驱动架构:
- 采用消息队列(如Kafka/Pulsar)或边缘设备事件触发器(如IoT传感器),实现毫秒级事件感知。
- 示例:工业质检Agent通过摄像头帧级事件实时捕捉产品缺陷。
- 流式数据处理:
- 集成流计算框架(Flink/Spark Streaming),对输入数据实时清洗与特征提取。
- 挑战:高并发场景下需平衡吞吐量与延迟(如自动驾驶需<100ms响应)。
- RAG流式更新知识
- 动态索引构建:
- 增量索引技术(如Elasticsearch的_update_by_query)支持文档级实时更新,避免全量重建索引的延迟。
- 优化点:结合向量数据库(Milvus/Pinecone)的相似度检索,确保新知识即时生效。
- 多级缓存策略:
- 热点知识缓存在内存(Redis),冷数据下沉至磁盘,平衡实时性与成本。
- 案例:金融风控Agent实时同步监管政策变更至缓存层。
- 动态索引构建:
- 工具层的实时性支持
- 低延迟工具调用:
- 工具API设计遵循轻量化原则(如gRPC替代REST),预加载工具上下文减少冷启动延迟。
- 示例:电商客服Agent调用库存API时,通过HTTP长连接保持会话状态。
- 异步执行与超时熔断:
- 工具调用采用异步协程(如Python asyncio),超时机制(如Hystrix)避免阻塞主线程。
- 低延迟工具调用:
- 数据层的实时性支持
- 实时数仓与OLAP优化:
- 使用实时OLAP引擎(ClickHouse/Doris)或时序数据库(InfluxDB),支持亚秒级聚合分析。
- 技术选型:Lambda架构兼顾实时流(Flink)与批处理(Hive)数据一致性。
- 分布式状态管理:
- 通过分布式快照(如Flink Checkpoint)保证Agent状态跨节点实时同步,避免决策偏差。
- 实时数仓与OLAP优化:
底层应用
底层应用是AI Agent的工具模块的一部分。由于上下文提示的影响,Agent也可能无法导向正确的知识,甚至产生知识幻觉。再加上缺乏语料库、训练数据以及针对特定领域和场景的调整,在专注于特定领域时,Agent的专业知识也会受到限制。专业化工具能让 LLM 以可插拔的形式增强其专业知识、调整领域知识并更适合特定领域的需求。
- 业务场景:
- 大数据应用:客户画像、数据血缘分析。
- 垂直业务:智能客服、精准营销、风险处置。
- 特点:直接解决具体业务问题,依赖下层技术支撑。
AI Agent智能体
- 架构核心:自主决策与协作系统。
- 关键设计:
- 单智能体:包含感知→决策→执行的闭环(如零售智能体的推荐逻辑)。
- 多智能体系统:通过通信模块协作(如风控+量化智能体联合决策)。
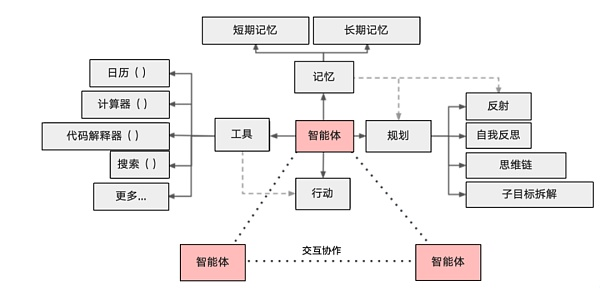
智能体组成
AI Agent(智能代理)是一个能够感知环境、自主决策并执行动作的智能系统,其核心组成和实现方式通常包括以下部分:
1. 感知模块(Perception)
- 作用:从环境中获取信息(如传感器数据、用户输入、网络数据等),并将其转化为结构化数据供其他模块处理。
- 实现方式:
- 传感器:物理设备(如摄像头、麦克风)或软件接口(API、网页爬虫)。
- 自然语言处理(NLP):解析文本或语音输入(如BERT、GPT)。
- 计算机视觉:处理图像/视频(如CNN、YOLO)。
- 数据预处理:清洗、归一化、特征提取等。
- 决策模块(Reasoning/Planning)
- 作用:基于感知信息、内部知识库和目标,制定行动策略或生成响应。
- 实现方式:
- 规则引擎:基于预定义规则(如专家系统)。
- 机器学习模型:通过强化学习(RL)、深度学习(DL)或符号逻辑推理(如Prolog)。
- 规划算法:如A*搜索、蒙特卡洛树搜索(MCTS)用于路径规划或任务分解。
- 大语言模型(LLM):如GPT-4生成对话或决策建议。
| 方法 | 优势 | 局限性 | 适用场景 | 技术依赖 |
|---|---|---|---|---|
| 规则引擎 | 透明、易解释 | 灵活性低,规则维护成本高 | 结构化流程(如审批) | 专家知识库 |
| 规划算法 | 支持多步骤任务分解 | 计算复杂,需环境模型 | 机器人导航、供应链优化 | 图搜索算法、动态规划 |
| 强化学习 | 自适应动态环境 | 训练成本高,奖励设计困难 | 游戏AI、实时控制 | 深度神经网络、模拟环境 |
| 大模型推理 | 泛化能力强,自然语言交互 | 可能产生幻觉,算力需求高 | 开放域问答、创意生成 | LLM、RAG、工具调用API |
基于大模型的决策方法:
- ReAct框架:交替执行推理(Reasoning)和行动(Acting),例如:* 思维链(CoT):引导LLM分步推理,提升复杂任务解决能力.例如: 用户:某个城市的 GDP 是否比全国平均值高?Agent(CoT):首先获取该城市的 GDP 数据 -> 获取全国 GDP 平均值 -> 进行比较 -> 生成答案。
1
2
3
4
5while not goal_achieved:
state = perceive() # 感知环境
thought = llm_reason(state) # 生成推理
action = decide(thought) # 选择动作
execute(action) # 执行
- 记忆模块(Memory)
- 作用:存储短期/长期信息,支持上下文理解和学习。
- 实现方式:
- 短期记忆:缓存当前会话的上下文(如对话历史)。
- 长期记忆:知识图谱、向量数据库(如FAISS)、SQL数据库。
- 检索增强生成(RAG):结合外部知识库提升回答准确性。
- 执行模块(Action)
- 作用:将决策转化为具体行动,影响环境或用户。
- 实现方式:
- 物理执行器:机器人控制电机、机械臂。
- 软件接口:调用API(如发送邮件、控制智能家居)。
- 自然语言输出:语音合成(TTS)或文本生成(如ChatGPT)。
- 学习模块(Learning)
- 作用:通过反馈优化行为(在线学习或离线训练)。
- 实现方式:
- 监督学习:标注数据训练模型(如分类任务)。
- 强化学习(RL):通过奖励机制调整策略(如AlphaGo)。
- 联邦学习:分布式数据下的隐私保护学习。
- 通信模块(Communication)
- 作用:与用户、其他Agent或系统交互。
- 实现方式:
- 自然语言交互:基于NLP的对话系统。
- 协议接口:HTTP/RPC、消息队列(如MQTT)。
Agent性能衡量
常见评估指标:
- 任务成功率(Task Completion Rate)
- 工具调用准确率(Tool Usage Accuracy)
- 推理质量(Reasoning Quality)
- 用户满意度(User Satisfaction)
多智能体
多智能体系统(Multi-Agent System, MAS)是由多个AI Agent组成的协作网络,这些Agent通过通信和协同工作,共同完成复杂任务。多智能体的核心优势在于:
1. 分工协作:不同Agent专精于特定任务(如搜索、数据分析、代码生成等),通过任务拆解和分配实现高效协同。
2. 复杂任务处理:单个Agent难以完成的复杂任务(如全域营销、供应链优化),可通过多Agent协作分阶段解决。
3. 适应性更强:动态环境中,多Agent系统能通过实时交互调整策略,例如无人机编队或金融风控场景。
架构设计
- 分层协作:参考Manus的三大模块:
- 规划模块:拆解任务并分配子任务(如将“旅游保险分析”拆解为PDF解析、数据对比等步骤)。
- 执行模块:调用专用Agent(如Content Agent生成报告)。
- 验证模块:审核结果准确性后交付用户。
- 通信协议:采用标准化框架(如InterAgent协议)确保Agent间互操作性,类似区块链中的智能合约协调。
开发框架与工具
- 开源平台:
- AutoGen:支持多Agent对话和人类参与,适合构建聊天机器人协作系统。
- CrewAI:强调流程化任务分配,适合顺序性强的场景(如自动发邮件流程)。
- MetaGPT:基于角色设计的框架,模拟软件开发团队分工。
- 商业化应用:如Manus的付费多Agent服务,或微盟的“数字员工”企业级解决方案。
案例
数据分析智能体
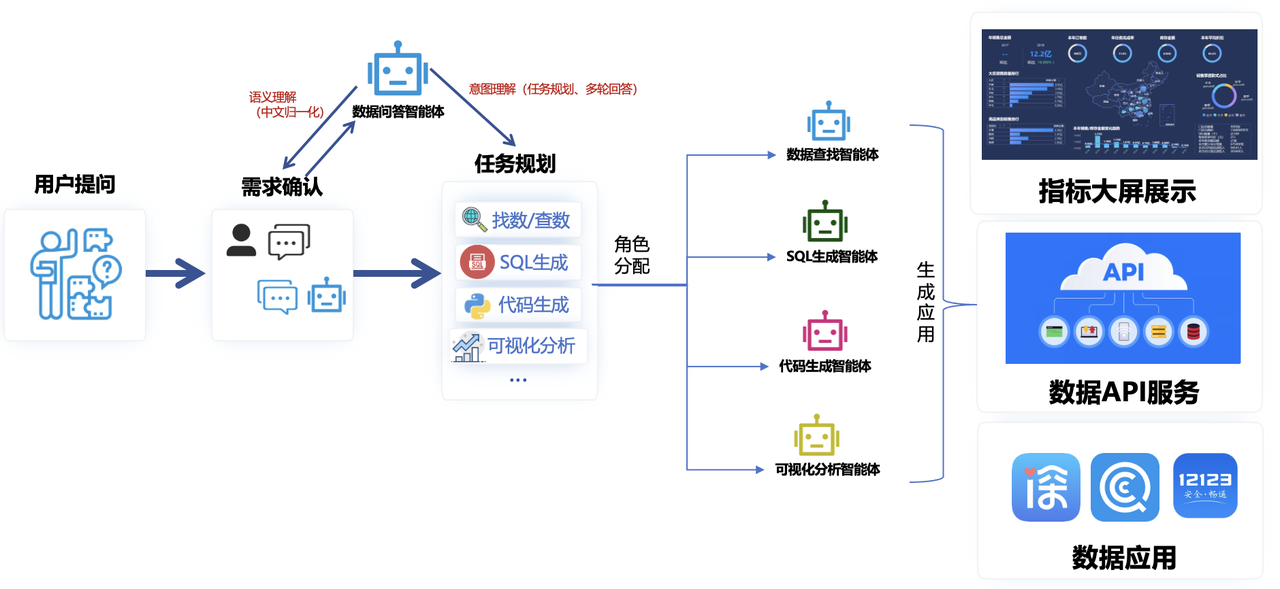
以下场景为deepseek生成。(从侧面体现了LLM的决策能力)
提示词:请你设计一个数据分析智能体,用对话的形式,实现“描述性分析”与“探索性分析”两种分析场景。能用到的工具有:数据地图,数据卡片平台,归因分析平台,客户画像系统,数据血缘,埋点平台、客群分析平台等
1 | 数据分析智能体对话设计 |
1 | flowchart LR |
可能的方向
- 员工效率提升
- 重复性工作:数据录入、报表生成、邮件分类等规则明确的流程。
- 预测分析:基于历史数据的销售预测、风险评估。
- 辅助性数据探索工作:ChatBI
- 实时响应:客服聊天机器人(如回答常见问题)。
- 信息处理与生成
- 内容创作:生成文本(研报、市场简报)、图像/视频合成(研报文生图)。
- 事件驱动分析:识别突发事件对行业的影响(如疫情对航空股冲击)。
- 知识检索:快速搜索并整合信息(投研问答)。
- 风险管理与合规
- 异常交易监测:识别操纵市场、老鼠仓等模式(如监测账户关联性)。
- 反洗钱(AML):AI分析资金流水,标记可疑交易
- 客户服务与营销
- 智能投顾:根据风险问卷生成标准化组合。
- 精准营销:通过用户行为分析推荐产品(如低风险客户推国债逆回购)。
- 合规质检:AI监听客服通话,实时提示违规话术(如承诺收益)。