大模型微调(Fine-tuning)是将预训练模型适配到特定任务或领域的关键技术,根据参数更新方式、资源需求和任务特性,主流方法可分为以下几类:
1. 全量微调(Full Fine-tuning)
- 原理:调整预训练模型的所有参数,使其完全适应新任务的数据分布。
- 优点:性能最优,适合与预训练目标差异大的任务。
- 缺点:计算资源消耗大,需大量标注数据(通常数万条),易过拟合。
- 适用场景:数据充足且资源丰富的任务(如医疗诊断、金融风险评估)。
2. 高效参数微调方法
(1) LoRA(低秩适配)
- 原理:在权重矩阵中引入低秩分解矩阵(如秩为8的矩阵A和B),仅微调少量参数,保持原始权重不变。
- 优点:参数效率高(仅更新0.1%参数),适合边缘设备部署。
- 适用场景:资源受限或需快速迭代的任务(如设备故障诊断)。
其它方法都有各自的一些问题:
- Adapter Tuning 增加了模型层数,引入了额外的推理延迟
- Prefix-Tuning 难于训练,且预留给 Prompt 的序列挤占了下游任务的输入序列空间,影响模型性能
- P-tuning v2 很容易导致旧知识遗忘,微调之后的模型,在之前的问题上表现明显变差
基于上述背景,LORA 得益于前人的一些关于内在维度(intrinsic dimension)的发现:
模型是过参数化的,它们有更小的内在维度,模型主要依赖于这个低的内在维度(low intrinsic dimension)去做任务适配。
假设模型在任务适配过程中权重的改变量是低秩(low rank)的,由此提出低秩自适应(LoRA)方法。
LoRA 允许我们通过优化适应过程中密集层变化的秩分解矩阵,来间接训练神经网络中的一些密集层,同时保持预先训练的权重不变。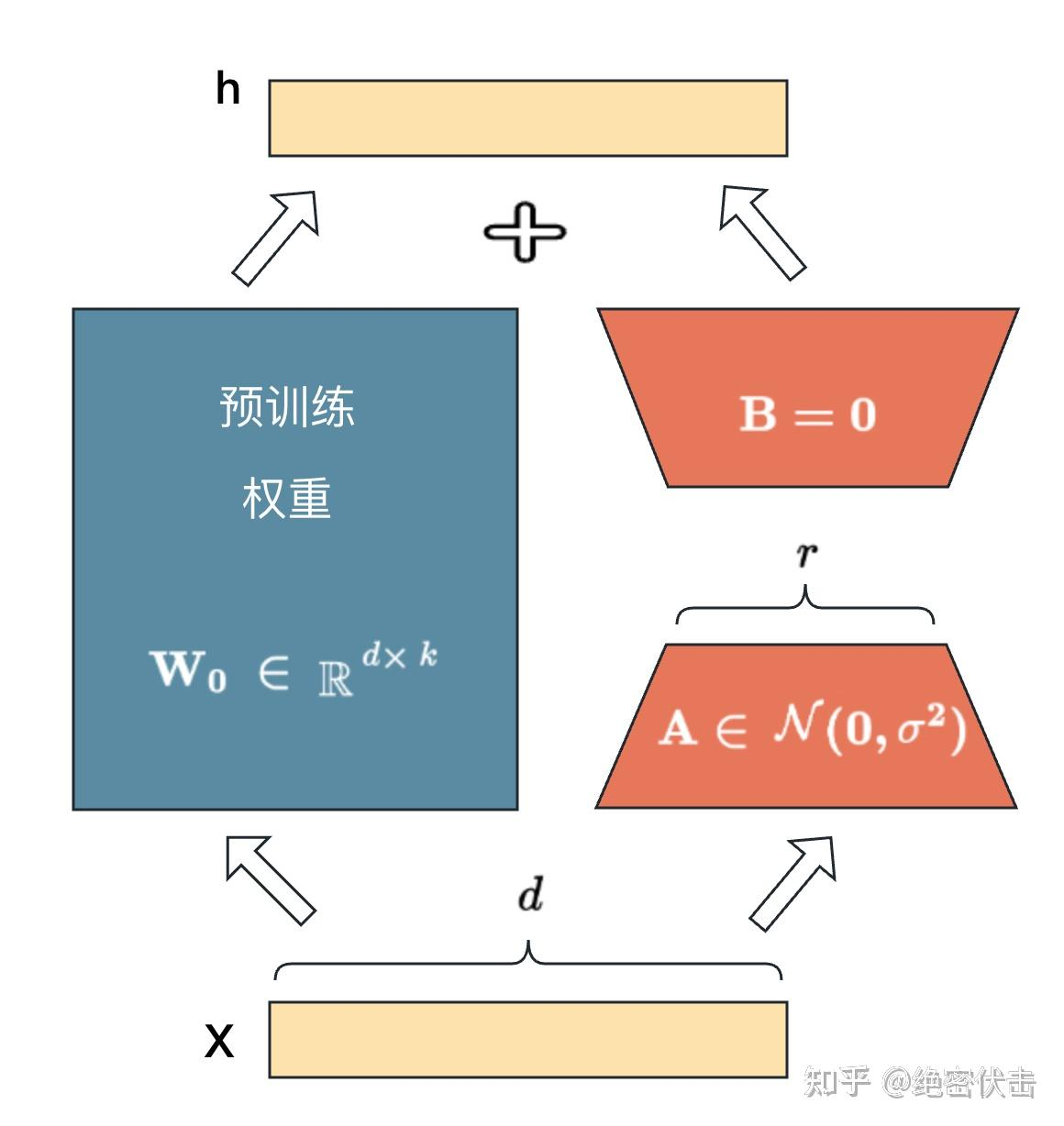
LoRA 的思想很简单:
- 在原始 PLM (Pre-trained Language Model) 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的intrinsic rank。
- 训练的时候固定 PLM 的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将AB与 PLM 的参数叠加。
- 用随机高斯分布初始化 A,用 0 矩阵初始化 B,保证训练的开始此旁路矩阵依然是 0 矩阵。
LoRA(Low-Rank Adaptation)之所以在微调大模型时效果显著,主要得益于其独特的低秩分解设计、高效的参数优化策略以及对模型知识的保护机制。以下是具体原因分析:
1. 低秩分解的数学优势
- 核心原理:LoRA通过将权重矩阵的更新量 (\Delta W) 分解为两个低秩矩阵 (A) 和 (B)((W’ = W + BA)),其中 (A) 和 (B) 的秩 (r) 远小于原始矩阵维度(如 (r=8))。这种分解将参数量从 (d \times k) 压缩至 (r \times (d+k)),实现97%以上的参数压缩率,同时保留95%以上的任务性能。
- 内在维度假设:大模型在适应新任务时,权重更新实际存在于一个低维子空间。实验证明,即使秩 (r=1),LoRA也能逼近全量微调的效果,验证了这一假设。
2. 资源效率与训练加速
- 极低参数量:以GPT-3为例,LoRA仅需训练原模型0.01%的参数(约百万级),显存消耗降低3倍,使得RTX 3090等消费级GPU也能微调70亿参数模型。
- 优化器效率:仅需维护低秩矩阵的梯度状态,减少优化器开销。例如,Adam优化器的内存占用大幅降低,训练速度比全量微调快3倍。
- 零推理延迟:训练后可将 (BA) 合并到原权重中,不增加额外计算层,推理速度与原始模型一致。
3. 知识保留与抗过拟合
- 冻结原权重:LoRA仅训练新增的低秩矩阵,预训练模型的核心知识不被破坏,避免了灾难性遗忘。例如,在医疗问答任务中,LoRA微调的LLaMA-7B模型准确率提升23%,同时保留通用语言能力。
- 正则化效果:低秩约束天然抑制过拟合,尤其在小样本场景下表现优异。实验显示,LoRA在文本分类任务上的F1分数比全量微调高4%。
4. 灵活性与通用性
- 模块化设计:支持多任务适配器叠加。例如,Stable Diffusion可通过不同LoRA模块生成赛博朋克或水墨风格,仅需20张图片训练。
- 广泛适配性:适用于Transformer的任意线性层(如注意力层的 (W_q) 和 (W_v)),且与量化技术(如QLoRA)、分布式训练兼容。
5. 实际应用验证
- 性能对比:在多项NLP任务中,LoRA与全量微调效果相当甚至更优。例如,GPT-3微调后ROUGE-L指标达89.65,而资源消耗仅为传统方法的1%。
- 工业级扩展:阿里云的动态权重融合技术结合LoRA,实现异构适配器并行效率提升40%。
(2) QLoRA(量化LoRA)
- 原理:结合4-bit量化和LoRA,进一步降低显存占用。
- 优点:支持单GPU微调百亿参数模型。
- 适用场景:超低资源环境(如移动端应用)。
(3) Adapter Tuning(适配器调整)
- 原理:在模型层间插入小型神经网络模块(Adapter),仅训练这些模块。
- 优点:模块化设计,支持多任务复用。
- 缺点:轻微增加推理延迟。
- 适用场景:多任务学习(如不同领域的文本分类)。
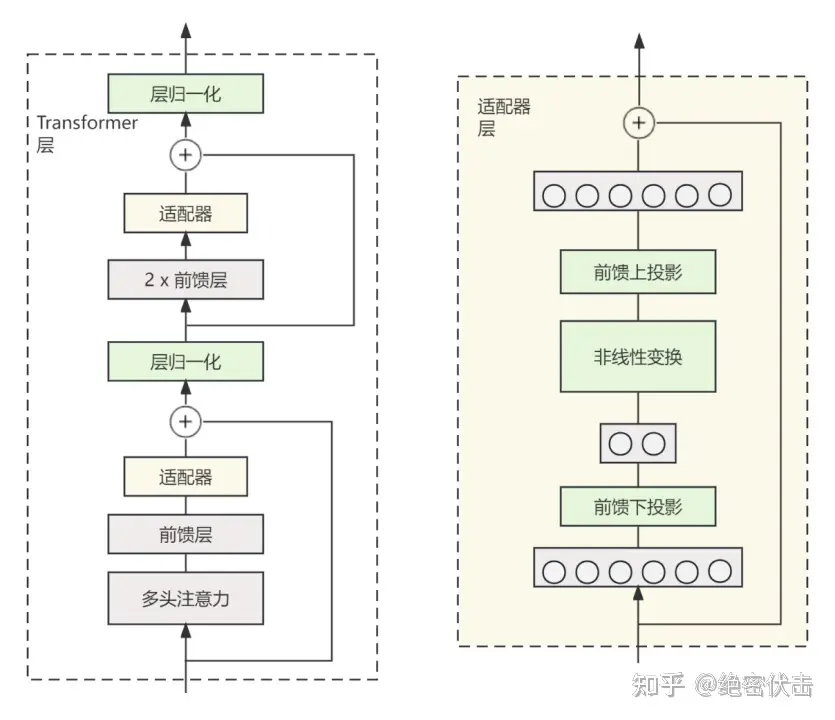
Adapter 结构,将其嵌入 Transformer 的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的 Adapter 结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数),他们将 Adapter 设计为这样的结构:
- 首先是一个 down-project 层将高维度特征映射到低维特征
- 然后过一个非线形层之后,再用一个 up-project 结构将低维特征映射回原来的高维特征
- 同时也设计了 skip-connection 结构,确保了在最差的情况下能够退化为identity(类似残差结构)。
从实验结果来看,该方法能够在只额外对增加的 3.6% 参数规模(相比原来预训练模型的参数量)的情况下取得和Full-Finetuning 接近的效果(GLUE指标在0.4%以内)。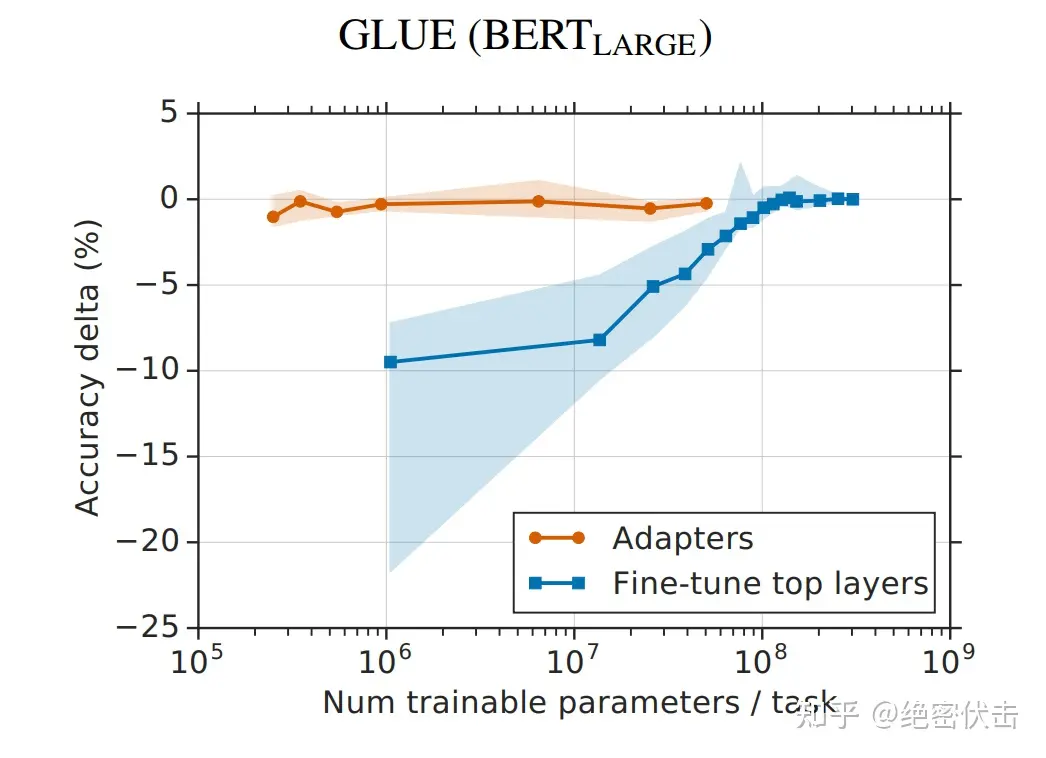
(4) Prefix/Prompt Tuning(前缀/提示调整)
- 原理:在输入中添加可学习的虚拟标记(Prefix或Prompt),通过调整这些标记引导模型输出。
- 优点:几乎不修改模型参数,适合快速任务切换。
- 缺点:效果依赖提示设计。
- 适用场景:生成式任务(如文本生成、对话系统)。
Prefix:
在输入 token 之前构造一段任务相关的 virtual tokens 作为 Prefix,然后训练的时候只更新 Prefix 部分的参数,而 Transformer 中的其他部分参数固定。该方法其实和构造 Prompt 类似,只是 Prompt 是人为构造的“显式”的提示,并且无法更新参数,而Prefix 则是可以学习的“隐式”的提示。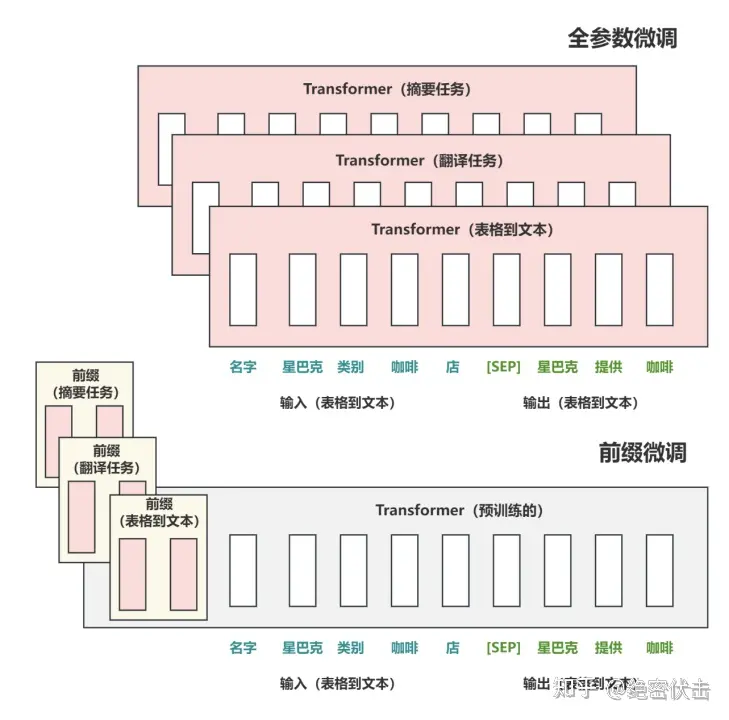
同时,为了防止直接更新 Prefix 的参数导致训练不稳定的情况,他们在 Prefix 层前面加了 MLP 结构(相当于将Prefix 分解为更小维度的 Input 与 MLP 的组合后输出的结果),训练完成后,只保留 Prefix 的参数。
Prompt :
是 Prefix Tuning 的简化版本,只在输入层加入 prompt tokens,并不需要加入 MLP 进行调整来解决难训练的问题,主要在 T5 预训练模型上做实验。似乎只要预训练模型足够强大,其他的一切都不是问题。作者也做实验说明随着预训练模型参数量的增加,Prompt Tuning的方法会逼近 Fine-tune 的结果。
固定预训练参数,为每一个任务额外添加一个或多个 embedding,之后拼接 query 正常输入 LLM,并只训练这些 embedding。左图为单任务全参数微调,右图为 Prompt tuning。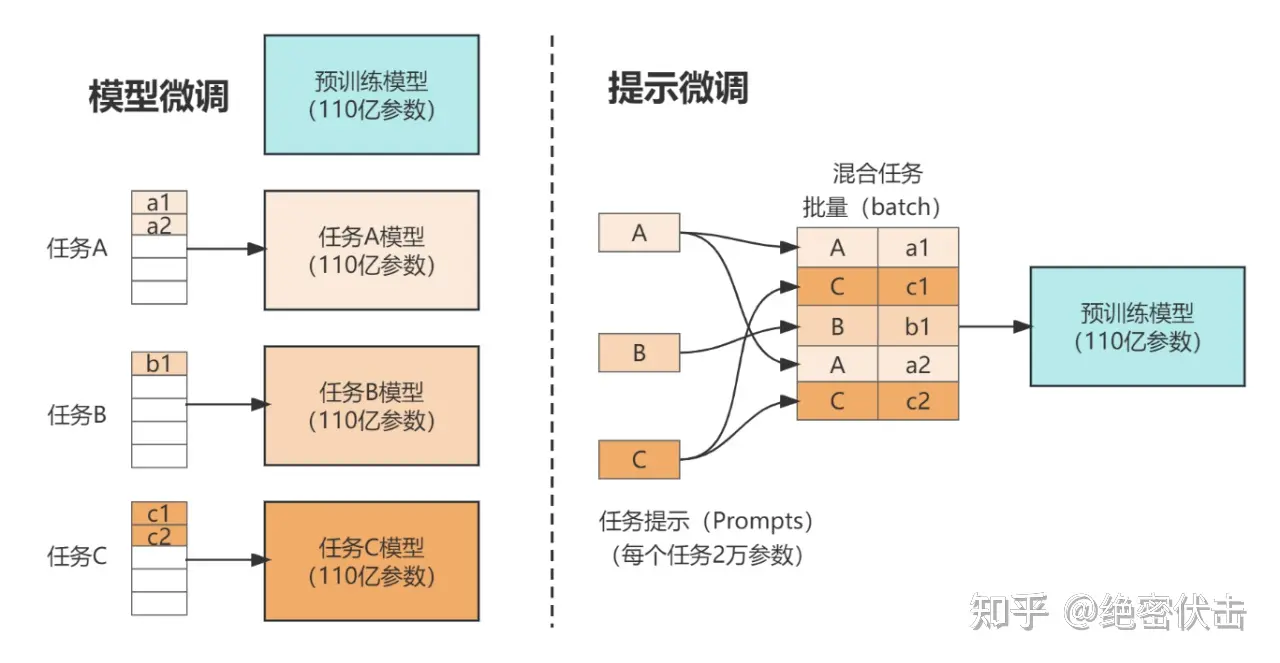

- Prompt 长度影响:模型参数达到一定量级时,Prompt 长度为1也能达到不错的效果,Prompt 长度为20就能达到极好效果。
- Prompt初始化方式影响:Random Uniform 方式明显弱于其他两种,但是当模型参数达到一定量级,这种差异也不复存在。
- 预训练的方式:LM Adaptation 的方式效果好,但是当模型达到一定规模,差异又几乎没有了。
- 微调步数影响:模型参数较小时,步数越多,效果越好。同样随着模型参数达到一定规模,zero shot 也能取得不错效果。
- 当参数达到100亿规模与全参数微调方式效果无异。
(5) BitFit(偏置微调)
- 原理:仅更新模型中的偏置(Bias)参数,冻结其他权重。
- 优点:极低资源消耗(更新1%参数)。
- 适用场景:简单分类任务或低资源场景。
3. 混合微调方法
- MAM Adapter:结合LoRA和Adapter,在不同模块应用不同技术。
- UniPELT:动态选择适配技术(如Adapter或Prefix Tuning)。
- 适用场景:复杂多任务或动态任务环境。
4. 知识蒸馏(Knowledge Distillation)
- 原理:通过小模型(学生)模仿大模型(教师)的行为,实现轻量化部署。
- 优点:减少推理成本,保留大部分性能。
- 适用场景:需高效推理的任务(如移动端问答系统)。
方法选择建议
| 场景 | 推荐方法 |
|---|---|
| 数据量大+资源充足 | 全量微调 |
| 小样本+低资源 | LoRA/Prompt Tuning |
| 多任务适配 | Adapter/MAM Adapter |
| 生成式任务 | Prefix Tuning |
| 超低资源 | BitFit/QLoRA |