Kudu
基本架构
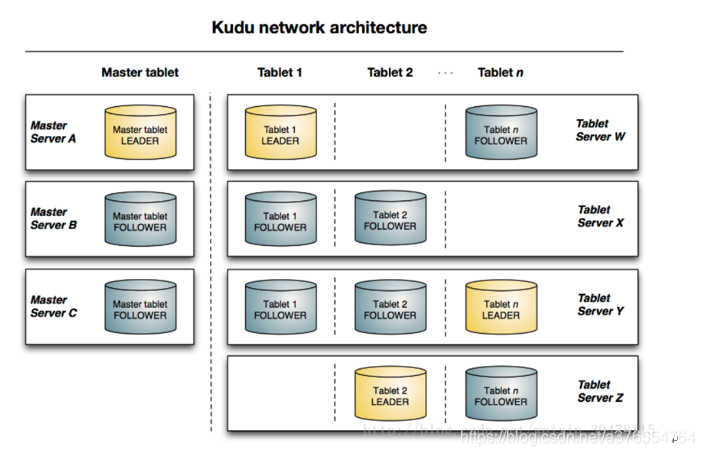
- Table(表):一张table是数据存储在kudu的位置。Table具有schema和全局有序的primary key(主键)。Table被分为很多段,也就是tablets.
- Tablet (段):一个tablet是一张table连续的segment,与其他数据存储引擎或关系型数据的partition相似。Tablet存在副本机制,其中一个副本为leader tablet。任何副本都可以对读取进行服务,并且写入时需要在所有副本对应的tablet server之间达成一致性。
- Tablet server:存储tablet和为tablet向client提供服务。对于给定的tablet,一个tablet server充当leader,其他tablet server充当该tablet的follower副本。只有leader服务写请求,leader与follower为每个服务提供读请求。
- Master:主要用来管理元数据(元数据存储在只有一个tablet的catalog table中),即tablet与表的基本信息,监听tserver的状态
- Catalog Table: 元数据表,用来存储table(schema、locations、states)与tablet(现有的tablet列表,每个tablet及其副本所处tserver,tablet当前状态以及开始和结束键)的信息。
存储结构
总的来说是LSM tree的结构

- 一个Table包含多个Tablet,其中Tablet的数量是根据hash或者range进行设置
- 一个Tablet中包含MetaData信息和多个RowSet信息
- 一个Rowset中包含一个MemRowSet与0个或多个DiskRowset,其中MemRowSet存储insert的数据,一旦MemRowSet写满会flush到磁盘生成一个或多个DiskRowSet,此时MemRowSet清空。MemRowSet默认写满1G或者120s flush一次
(注意:memRowSet是行式存储,DiskRowSet是列式存储,MemRowSet基于primary key有序)。每隔tablet中会定期对一些diskrowset做compaction操作,目的是对多个diskRowSet进行重新排序,以此来使其更有序并减少diskRowSet的数量,同时在compaction的过程中慧慧resolve掉deltaStores当中的delete记录 - 一个DiskRowSet包含baseData与DeltaStores两部分,其中baseData存储的数据看起来不可改变,DeltaStores中存储的是改变的数据
- DeltaStores包含一个DeltaMemStores和多个DeltaFile,其中DeltaMemStores放在内存,用来存储update与delete数据,一旦DeltaMemStores写满,会flush成DeltaFile。
当DeltaFile过多会影响查询性能,所以KUDU每隔一段时间会执行compaction操作,将其合并到baseData中,主要是resolve掉update数据。
写入

读取
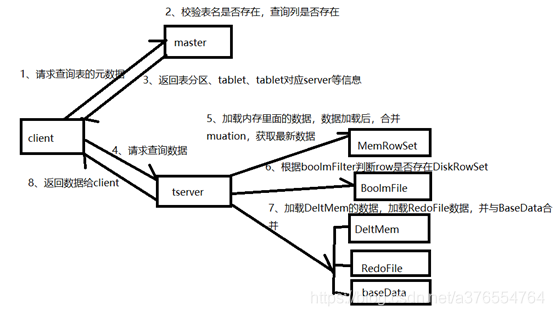
- 客户端master请求查询表指定数据
- master对请求进行校验,校验表是否存在,schema中是否存在指定查询的字段,主键是否存在
- master通过查询catalog Table返回表,将tablet对应的tserver信息、tserver状态等元数据信息返回给client
- client与tserver建立连接,通过metaData找到primary key对应的RowSet。
- 首先加载RowSet内存中MemRowSet与DeltMemStore中的数据
- 然后加载磁盘中的数据,也就是DiskRowSet中的BaseData与DeltFile中的数据
- 返回数据给Client
- 继续4-7步骤,直到拿到所有数据返回给client
插入
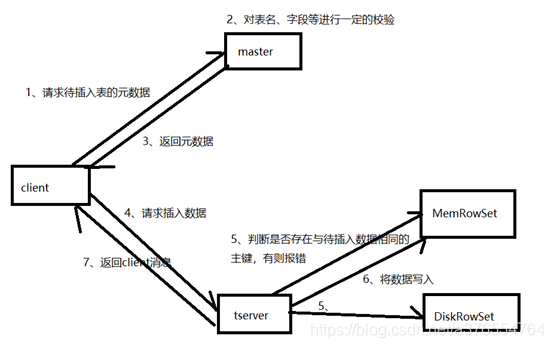
- client向master请求预写表的元数据信息
- master会进行一定的校验,表是否存在,字段是否存在等
- 如果master校验通过,则返回表的分区、tablet与其对应的tserver给client;如果校验失败则报错给client。
- client根据master返回的元数据信息,将请求发送给tablet对应的tserver.
- tserver首先会查询内存中MemRowSet与DeltMemStore中是否存在与待插入数据主键相同的数据,如果存在则报错
- tserver会讲写请求预写到WAL日志,用来server宕机后的恢复操作
- 将数据写入内存中的MemRowSet中,一旦MemRowSet的大小达到1G或120s后,MemRowSet会flush成一个或DiskRowSet,用来将数据持久化
- 返回client数据处理完毕
更新

- client向master请求预更新表的元数据,首先master会校验表是否存在,字段是否存在,如果校验通过则会返回给client表的分区. tablet. tablet所在tserver信息
- client向tserver发起更新请求
- 将更新操作预写如WAL日志,用来在server宕机后的数据恢复
- 根据tserver中待更新的数据所处位置的不同,有不同的处理方式:
如果数据在内存中,则从MemRowSet中找到数据所处的行,然后在改行的mutation链表中写入更新信息,在MemRowSet flush的时候,将更新合并到baseData中
如果数据在DiskRowSet中,则将更新信息写入DeltMemStore中,DeltMemStore达到一定大小后会flush成DeltFile。 - 更新完毕后返回消息给client。
使用场景
- 流式实时计算场景
流式计算场景通常有持续不断地大量写入,与此同时这些数据还要支持近乎实时的读、写以及更新操作。Kudu的设计能够很好的处理此场景。 - 时间序列存储引擎(TSDB)
Kudu的hash分片设计能够很好地避免TSDB类请求的局部热点问题。同时高效的Scan性能让Kudu能够比Hbase更好的支持查询操作。 - 机器学习&数据挖掘
机器学习和数据挖掘的中间结果往往需要高吞吐量的批量写入和读取,同时会有少量的随机读写操作。Kudu的设计可以很好地满足这些中间结果的存储需求。 - 与历史遗产数据共存
在工业界实际生产环境中,往往有大量的历史遗产数据。Impala可以同时支持HDFS、Kudu等多个底层存储引擎,这个特性使得在使用的Kudu的同时,不必把所有的数据都迁移到Kudu。 - Kudu+Impala为实时数据仓库存储提供了良好的解决方案。这套架构在支持随机读写的同时还能保持良好的Scan性能,同时其对Spark等流式计算框架有官方的客户端支持。这些特性意味着数据可以从Spark实时计算中实时的写入Kudu,上层的Impala提供BI分析SQL查询,对于数据挖掘和算法等需求可以在Spark迭代计算框架上直接操作Kudu底层数据。