基本架构
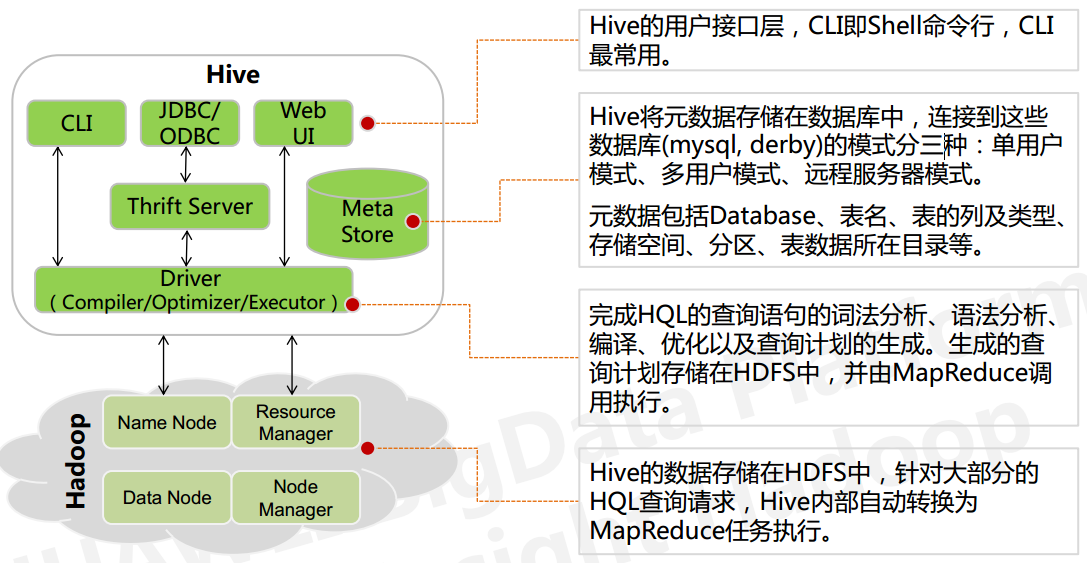
- 用户接口: shell/CLI, jdbc/odbc, webui Command Line Interface
- 跨语言服务 : thrift server 提供了一种能力,让用户可以使用多种不同的语言来操纵hive
- Driver
Driver 组件完成 HQL 查询语句从词法分析,语法分析,编译,优化,以及生成逻辑执行 计划的生成。生成的逻辑执行计划存储在 HDFS 中,并随后由 MapReduce 调用执行
Hive 的核心是驱动引擎, 驱动引擎由四部分组成:- 解释器:解释器的作用是将 HiveSQL 语句转换为抽象语法树(AST)
- 编译器:编译器是将语法树编译为逻辑执行计划
- 优化器:优化器是对逻辑执行计划进行优化
- 执行器:执行器是调用底层的运行框架执行逻辑执行计划
- 元数据存储系统 : RDBMS MySQL
元数据,通俗的讲,就是存储在 Hive 中的数据的描述信息。
Hive 中的元数据通常包括:表的名字,表的列和分区及其属性,表的属性(内部表和 外部表),表的数据所在目录
Metastore 默认存在自带的 Derby 数据库中。缺点就是不适合多用户操作,并且数据存 储目录不固定。数据库跟着 Hive 走,极度不方便管理
解决方案:通常存我们自己创建的 MySQL 库(本地 或 远程)
Hive 和 MySQL 之间通过 MetaStore 服务交互
执行流程:
HiveQL 通过命令行或者客户端提交,经过 Compiler 编译器,运用 MetaStore 中的元数 据进行类型检测和语法分析,生成一个逻辑方案(Logical Plan),然后通过的优化处理,产生 一个 MapReduce 任务。
数据组织
- Hive 的存储结构包括数据库、表、视图、分区和表数据等。数据库,表,分区等等都对 应 HDFS 上的一个目录。表数据对应 HDFS 对应目录下的文件。
- Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式,因为 Hive 是读模式 (Schema On Read),可支持 TextFile,SequenceFile,RCFile 或者自定义格式等
- 只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据
Hive 的默认列分隔符:控制符 Ctrl + A,\x01 Hive 的
Hive 的默认行分隔符:换行符 \n - Hive 中包含以下数据模型:
database:在 HDFS 中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在 HDFS 中表现所属 database 目录下一个文件夹
external table:与 table 类似,不过其数据存放位置可以指定任意 HDFS 目录路径
partition:在 HDFS 中表现为 table 目录下的子目录
bucket:在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散 列之后的多个文件
view:与传统数据库类似,只读,基于基本表创建 - Hive 的元数据存储在 RDBMS 中,除元数据外的其它所有数据都基于 HDFS 存储。默认情 况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的 测试。实际生产环境中不适用,为了支持多用户会话,则需要一个独立的元数据库,使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
- Hive 中的表分为内部表、外部表、分区表和 Bucket 表
外部表示hive 对存储在 HDFS 上的数据提供了一种新的抽象。而不是管理存储在 HDFS 上的数据。所以不管创建内部 表还是外部表,都可以对 hive 表的数据存储目录中的数据进行增删操作。- 内部表和外部表的区别:
- 删除内部表,删除表元数据和数据
- 删除外部表,删除元数据,不删除数据
- 内部表和外部表的使用选择:
- 大多数情况,他们的区别不明显,如果数据的所有处理都在 Hive 中进行,那么倾向于 选择内部表,但是如果 Hive 和其他工具要针对相同的数据集进行处理,外部表更合适。
- 使用外部表访问存储在 HDFS 上的初始数据,然后通过 Hive 转换数据并存到内部表中
- 使用外部表的场景是针对一个数据集有多个不同的 Schema
- 分区表和分桶表的区别:
Hive 数据表可以根据某些字段进行分区操作,细化数据管理,可以让部分查询更快。同 时表和分区也可以进一步被划分为 Buckets,分桶表的原理和 MapReduce 编程中的 HashPartitioner 的原理类似。
分区和分桶都是细化数据管理,但是分区表是手动添加区分,由于 Hive 是读模式,所 以对添加进分区的数据不做模式校验,分桶表中的数据是按照某些分桶字段进行 hash 散列 形成的多个文件,所以数据的准确性也高很多
- 内部表和外部表的区别:
元数据表
hive版本
VERSION表,记录hive版本
数据库相关meta表
| 表名 | 说明 | 字段 |
|---|---|---|
| DBS | 该表存储Hive中所有数据库的基本信息 | 数据库ID,数据库描述,数据库HDFS路径,数据库名,数据库所有者用户名,所有者角色 |
| DATABASE_PARAMS | 该表存储数据库的相关参数,在CREATE DATABASE时候用WITH DBPROPERTIES (property_name=property_value, …)指定的参数 | 数据库ID,参数名,参数值 |
DBS和DATABASE_PARAMS这两张表通过DB_ID字段关联。
表相关meta表
| 表名 | 说明 | 字段 |
|---|---|---|
| TBLS | 该表中存储Hive表、视图、索引表的基本信息 | 表ID,创建时间,数据库ID,上次访问时间,所有者,保留字段,序列化配置信息,表名,表类型,视图的详细HQL语句,视图的原始HQL语句 |
| TABLE_PARAMS | 该表存储表/视图的属性信息 | 表ID,属性名,属性值 |
| TBL_PRIVS | 该表存储表/视图的授权信息 | 授权ID,授权时间,授权执行用户,授权者类型,被授权用户,被授权用户类型,权限,表ID |
文件存储信息相关的元数据表
由于HDFS支持的文件格式很多,而建Hive表时候也可以指定各种文件格式,Hive在将HQL解析成MapReduce时候,需要知道去哪里,使用哪种格式去读写HDFS文件,而这些信息就保存在这几张表中。
| 表名 | 说明 | 字段 |
|---|---|---|
| SDS | 该表保存文件存储的基本信息,如INPUT_FORMAT、OUTPUT_FORMAT、是否压缩等。TBLS表中的SD_ID与该表关联,可以获取Hive表的存储信息 | |
| SD_PARAMS | 该表存储Hive存储的属性信息,在创建表时候使用STORED BY ‘storage.handler.class.name’ [WITH SERDEPROPERTIES (…)指定 | |
| SERDES | 该表存储序列化使用的类信息 | |
| SERDE_PARAMS | 该表存储序列化的一些属性、格式信息,比如:行、列分隔符 |
表字段相关的元数据表
| 表名 | 说明 | 字段 |
|---|---|---|
| COLUMNS_V2 | 该表存储表对应的字段信息 |
表分区相关的元数据表
| 表名 | 说明 | 字段 |
|---|---|---|
| PARTITIONS | 该表存储表分区的基本信息 | |
| PARTITION_KEYS | 该表存储分区的字段信息 | |
| PARTITION_KEY_VALS | 该表存储分区字段值 | |
| PARTITION_PARAMS | 该表存储分区的属性信息 |
数据类型与存储格式
基本数据类型
| 类型 | 描述 | 示例 |
|---|---|---|
| boolean | true/false | TRUE |
| tinyint | 1字节的有符号整数 | -128~127 1Y |
| smallint | 2个字节的有符号整数,-32768~32767 | 1S |
| int | 4个字节的带符号整数 | 1 |
| bigint | 8字节带符号整数 | 1L |
| float | 4字节单精度浮点数 | 1.0 |
| double | 8字节双精度浮点数 | 1.0 |
| deicimal | 任意精度的带符号小数 | 1.0 |
| String | 字符串,变长 | “a”,’b’ |
| varchar | 变长字符串 | “a”,’b’ |
| char | 固定长度字符串 | “a”,’b’ |
| binary | 字节数组 | 无法表示 |
| timestamp | 时间戳,纳秒精度 | 122327493795 |
| date | 日期 | ‘2018-04-07’ |
复杂数据类型
| 类型 | 描述 | 示例 |
|---|---|---|
| array | 有序的的同类型的集合 | array(1,2) |
| map | key-value,key必须为原始类型,value可以任意类型 | map(‘a’,1,’b’,2) |
| struct | 字段集合,类型可以不同 | struct(‘1’,1,1.0), named_stract(‘col1’,’1’,’col2’,1,’clo3’,1.0) |
存储格式
Hive会为每个创建的数据库在HDFS上创建一个目录,该数据库的表会以子目录形式存储,表中的数据会以表目录下的文件形式存储。对于default数据库,默认的缺省数据库没有自己的目录,default数据库下的表默认存放在/user/hive/warehouse目录下。
- textfile
textfile为默认格式,存储方式为行存储。数据不做压缩,磁盘开销大,数据解析开销大。 - SequenceFile
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。 - RCFile
一种行列存储相结合的存储方式。 - ORCFile
数据按照行分块,每个块按照列存储,其中每个块都存储有一个索引。hive给出的新格式,属于RCFILE的升级版,性能有大幅度提升,而且数据可以压缩存储,压缩快 快速列存取。 - Parquet
Parquet也是一种行式存储,同时具有很好的压缩性能;同时可以减少大量的表扫描和反序列化的时间。
数据格式
当数据存储在文本文件中,必须按照一定格式区别行和列,并且在Hive中指明这些区分符。Hive默认使用了几个平时很少出现的字符,这些字符一般不会作为内容出现在记录中。
Hive默认的行和列分隔符如下表所示。
| 分隔符 | 描述 |
|---|---|
| \n | 对于文本文件来说,每行是一条记录,所以\n 来分割记录 |
| ^A (Ctrl+A) | 分割字段,也可以用\001 来表示 |
| ^B (Ctrl+B) | 用于分割 Arrary 或者 Struct 中的元素,或者用于 map 中键值之间的分割,也可以用\002 分割。 |
| ^C | 用于 map 中键和值自己分割,也可以用\003 表示。 |
DDL
数据库DDL
- 创建库
- 查看库
- 删除库
- 切换库
表DDL
创建表:
1 | CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name |
- CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXIST 选项来忽略这个异常
- EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)
- LIKE 允许用户复制现有的表结构,但是不复制数据
- COMMENT可以为表与字段增加描述
- PARTITIONED BY 指定分区
- ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES
(property_name=property_value, property_name=property_value, …)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,
用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。 - STORED AS
SEQUENCEFILE //序列化文件
| TEXTFILE //普通的文本文件格式
| RCFILE //行列存储相结合的文件
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname //自定义文件格式
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCE 。 - LOCATION指定表在HDFS的存储路径
查看表
修改表
删除表
清空表
函数&脚本
内置函数
窗口函数
窗口函数是用于分析用的一类函数,要理解窗口函数要先从聚合函数说起。 大家都知道聚合函数是将某列中多行的值合并为一行,比如sum、count等。 而窗口函数则可以在本行内做运算,得到多行的结果,即每一行对应一行的值。 通用的窗口函数可以用下面的语法来概括:
Function() Over (Partition By Column1,Column2,Order By Column3)
窗口函数又分为以下三类: 聚合型窗口函数 分析型窗口函数 * 取值型窗口函数
聚合型窗口函数
聚合型即SUM(), MIN(),MAX(),AVG(),COUNT()这些常见的聚合函数。 聚合函数配合窗口函数使用可以使计算更加灵活
分析型窗口函数
分析型即RANk(),ROW_NUMBER(),DENSE_RANK()等常见的排序用的窗口函数
row_number函数:生成连续的序号(相同元素序号相同)
rank函数:如两元素排序相同则序号相同,并且会跳过下一个序号
desrank函数:如两元素排序相同则序号相同,不会跳过下一个序号
取值型窗口函数
这几个函数可以通过字面意思记得,LAG是迟滞的意思,也就是对某一列进行往后错行;LEAD是LAG的反义词,也就是对某一列进行提前几行;FIRST_VALUE是对该列到目前为止的首个值,而LAST_VALUE是到目前行为止的最后一个值。
LAG()和LEAD() 可以带3个参数,第一个是返回的值,第二个是前置或者后置的行数,第三个是默认值。
窗口大小
关键是理解 ROWS BETWEEN 含义,也叫做window子句:
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:无边界,UNBOUNDED PRECEDING 表示从最前面的起点开始, UNBOUNDED FOLLOWING:表示到最后面的终点
–其他AVG,MIN,MAX,和SUM用法一样
自定义函数
当 Hive 提供的内置函数无法满足业务处理需要时,此时就可以考虑使用用户自定义函数。
- UDF(user-defined function)作用于单个数据行,产生一个数据行作为输出。(数学函数,字 符串函数)
- UDAF(用户定义聚集函数 User- Defined Aggregation Funcation):接收多个输入数据行,并产 生一个输出数据行。(count,max)
- UDTF(表格生成函数 User-Defined Table Functions):接收一行输入,输出多行(explode)
1 | import org.apache.hadoop.hive.ql.exec.UDF; |
Transform
Hive 的 TRANSFORM 关键字提供了在 SQL 中调用自写脚本的功能。适合实现 Hive 中没有的 功能又不想写 UDF 的情况
1 | #!/bin/python |
1 | hive>add file /home/hadoop/weekday_mapper.py; |
数据倾斜
由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点
hive框架的特性:
- 不怕数据大,怕数据倾斜
- Jobs 数比较多的作业运行效率相对比较低,如子查询比较多
- sum,count,max,min 等聚集函数,通常不会有数据倾斜问题
主要表现:
任务进度长时间维持在 99%或者 100%的附近,查看任务监控页面,发现只有少量 reduce 子任务未完成,因为其处理的数据量和其他的 reduce 差异过大。 单一 reduce 处理的记录数和平均记录数相差太大,通常达到好几倍之多,最长时间远大 于平均时长。
容易出现数据倾斜的情况:
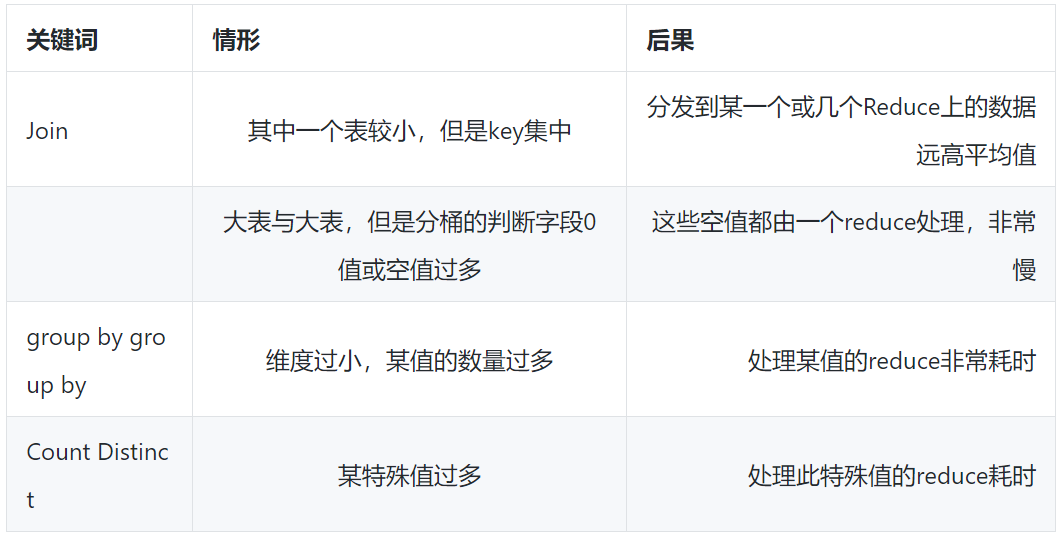
- group by 不和聚集函数搭配使用的时候
- count(distinct),在数据量大的情况下,容易数据倾斜,因为 count(distinct)是按 group by 字段分组,按 distinct 字段排序
- 小表关联超大表 join
产生数据倾斜的原因
- key 分布不均匀
- 业务数据本身的特性
- 建表考虑不周全
- 某些 HQL 语句本身就存在数据倾斜
解决办法
参数调节
hive.map.aggr=true
Map 端部分聚合,相当于Combiner
hive.groupby.skewindata=true
有数据倾斜的时候进行负载均衡,当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
语句调节
- 如何Join:
关于驱动表的选取,选用join key分布最均匀的表作为驱动表
做好列裁剪和filter操作,以达到两表做join的时候,数据量相对变小的效果。 - 大小表Join:
使用mapjoin让小的维度表(1000条以下的记录条数)先进内存。在map端完成reduce.
MAPJION会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配,而普通的equality join则是类似于mapreduce模型中的file join,需要先分组,然后再reduce端进行连接,使用的时候需要结合着场景;由于mapjoin是在map是进行了join操作,省去了reduce的运行,效率也会高很多 - 大表Join大表:
把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终结果。 - count distinct大量相同特殊值
count distinct时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。 - group by维度过小:
采用sum() group by的方式来替换count(distinct)完成计算。 - 特殊情况特殊处理:
在业务逻辑优化效果的不大情况下,有些时候是可以将倾斜的数据单独拿出来处理。最后union回去。
例子
- 空值产生的数据倾斜
在日志中,常会有信息丢失的问题,比如日志中的 user_id,如果取其中的 user_id 和用户表中的 user_id 相关联,就会碰到数据倾斜的问题。
解决方案 1:user_id 为空的不参与关联
解决方案 2:赋予空值新的 key 值 - 不同数据类型关联产生数据倾斜
用户表中 user_id 字段为 int,log 表中 user_id 为既有 string 也有 int 的类型, 当按照两个表的 user_id 进行 join 操作的时候,默认的 hash 操作会按照 int 类型的 id 进 行分配,这样就会导致所有的 string 类型的 id 就被分到同一个 reducer 当中
解决方案:把数字类型 id 转换成 string 类型的 id - 大小表关联查询产生数据倾斜
使用map join解决小表关联大表造成的数据倾斜问题。这个方法使用的频率很高。
hive执行过程
概述
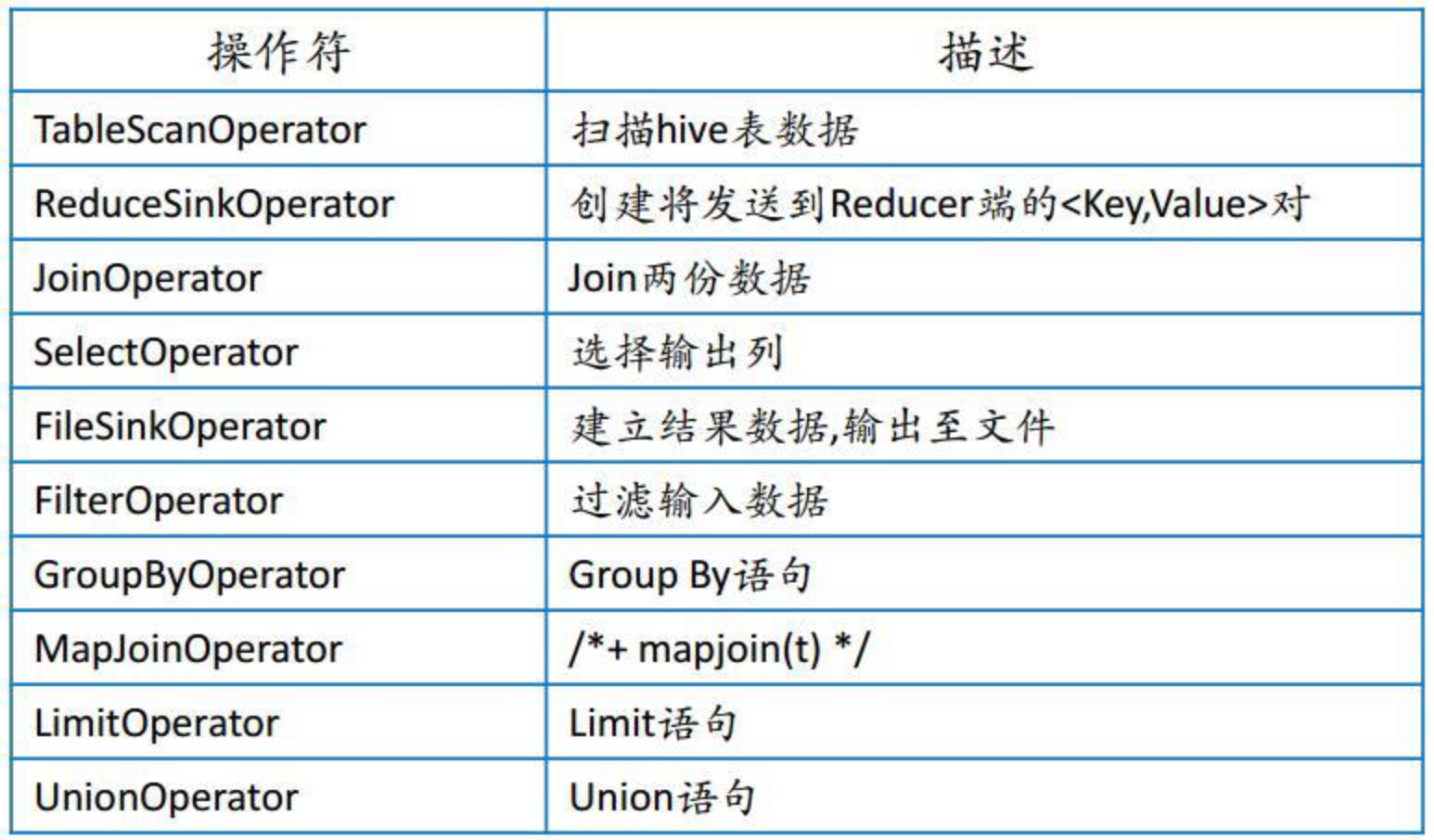
- Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等
- 操作符 Operator 是 Hive 的最小处理单元
- 每个操作符代表一个 HDFS 操作或者 MapReduce 作业
- Hive 通过 ExecMapper 和 ExecReducer 执行 MapReduce 程序,执行模式有本地模式和分 布式两种模式
操作符类型
编译器的工作职责
- Parser:将 HQL 语句转换成抽象语法树(AST:Abstract Syntax Tree)
- Semantic Analyzer:将抽象语法树转换成查询块
- Logic Plan Generator:将查询块转换成逻辑查询计划
- Logic Optimizer:重写逻辑查询计划,优化逻辑执行计划。优化过程可能包括谓词下推(Predicate Push Down),分区剪裁(Partition Prunner),关联排序(Join Reorder)
- Physical Plan Gernerator:将逻辑计划转化成物理计划(MapReduce Jobs)
- Physical Optimizer:选择最佳的 Join 策略,优化物理执行计划。比如基于输入选择执行路径,增加备份作业等
优化器类型
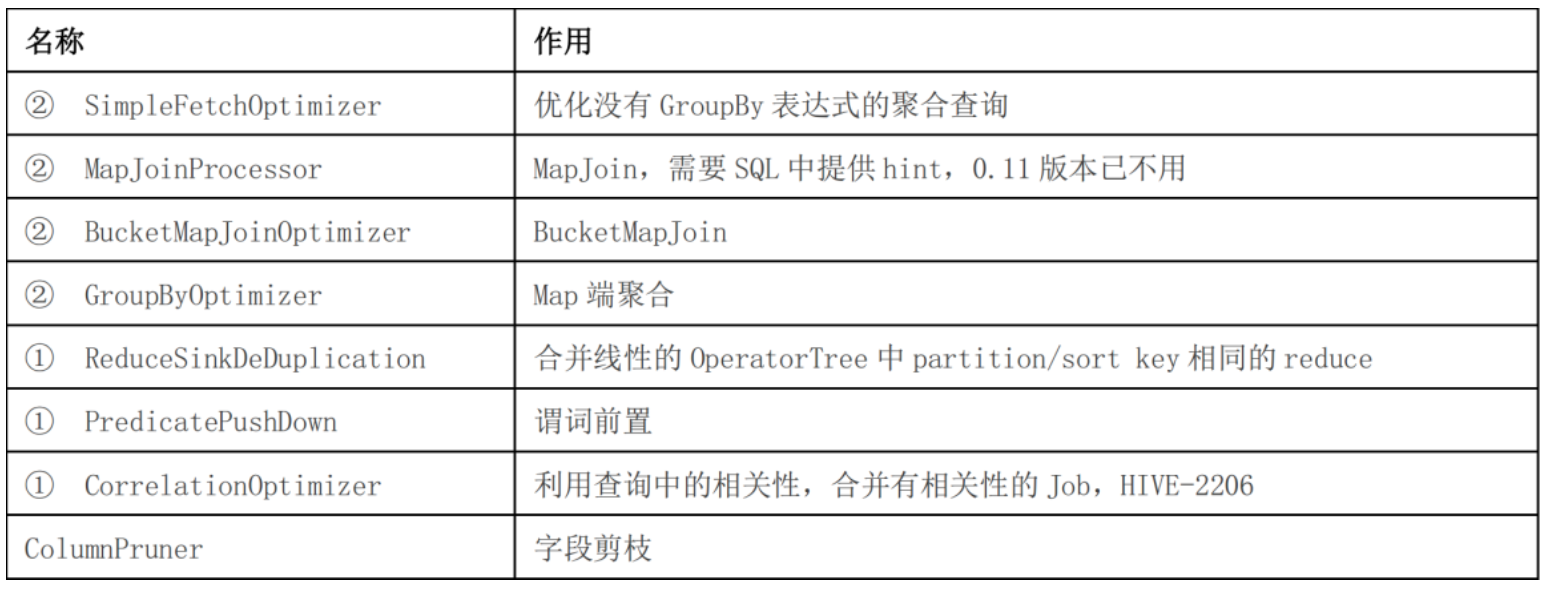
上表中带①符号的,优化目的都是尽量将任务合并到一个 Job 中,以减少 Job 数量,带②的 优化目的是尽量减少 shuffle 数据量
Join
Map:
- 以 JOIN ON 条件中的列作为 Key,如果有多个列,则 Key 是这些列的组合
- 以 JOIN 之后所关心的列作为 Value,当有多个列时,Value 是这些列的组合。在 Value 中还会包含表的 Tag 信息,用于标明此 Value 对应于哪个表
- 按照 Key 进行排序
Shuffle:
根据 Key 的值进行 Hash,并将 Key/Value 对按照 Hash 值推至不同对 Reduce 中
Reduce:
Reducer 根据 Key 值进行 Join 操作,并且通过 Tag 来识别不同的表中的数据
例子:
SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON pv.userid = u.userid;
%!(EXTRA markdown.ResourceType=, string=, string=)
Group By
实例:
SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age;
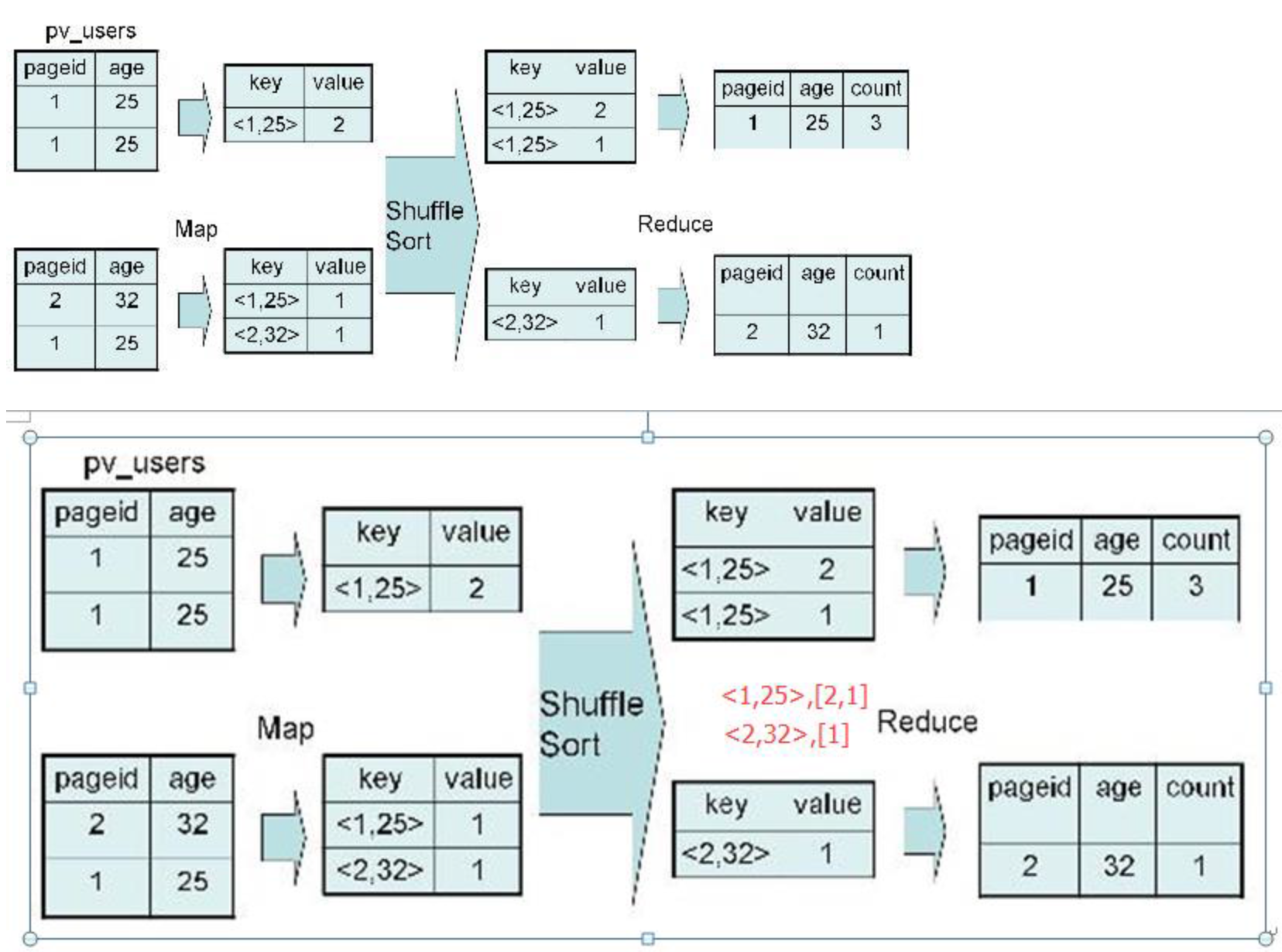
distinct
示例:
SELECT age, count(distinct pageid) FROM pv_users GROUP BY age;
按照 age 分组,然后统计每个分组里面的不重复的 pageid 有多少个
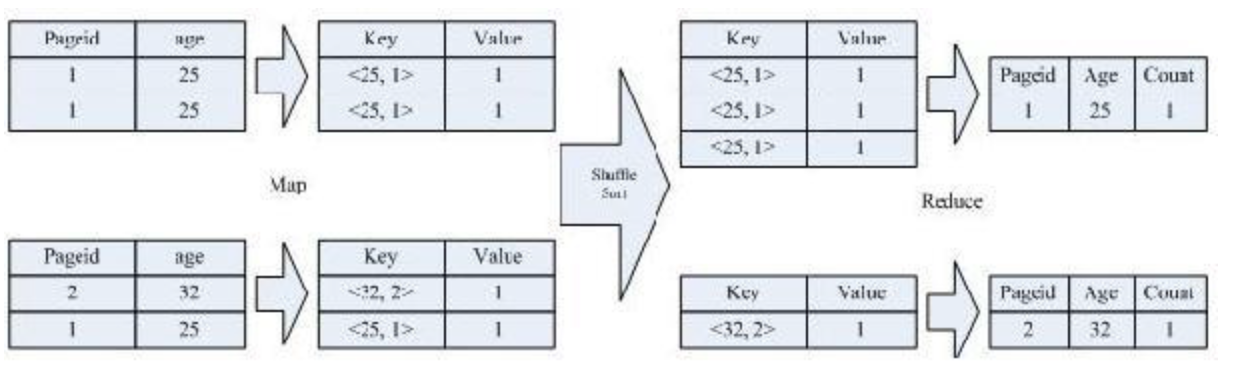
该 SQL 语句会按照 age 和 pageid 预先分组,进行 distinct 操作。然后会再按 照 age 进行分组,再进行一次 distinct 操作
优化
常用手段
- 好的模型设计事半功倍
- 解决数据倾斜问题
- 减少 job 数
- 设置合理的 MapReduce 的 task 数,能有效提升性能。(比如,10w+级别的计算,用 160个 reduce,那是相当的浪费,1 个足够)
- 了解数据分布,自己动手解决数据倾斜问题是个不错的选择。这是通用的算法优化,但 算法优化有时不能适应特定业务背景,开发人员了解业务,了解数据,可以通过业务逻辑精 确有效的解决数据倾斜问题
- 数据量较大的情况下,慎用 count(distinct),group by 容易产生倾斜问题
- 对小文件进行合并,是行之有效的提高调度效率的方法,假如所有的作业设置合理的文件数,对云梯的整体调度效率也会产生积极的正向影响
- 优化时把握整体,单个作业最优不如整体最优
排序选择
- cluster by:对同一字段分桶并排序,不能和 sort by 连用。cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是倒叙排序,不能指定排序规则为ASC或者DESC。
- distribute by + sort by:distribute by是控制在map端如何拆分数据给reduce端的。hive会根据distribute by后面列,对应reduce的个数进行分发,默认是采用hash算法。sort by为每个reduce产生一个排序文件。在有些情况下,你需要控制某个特定行应该到哪个reducer,这通常是为了进行后续的聚集操作。distribute by刚好可以做这件事。因此,distribute by经常和sort by配合使用
- sort by:sort by不是全局排序,其在数据进入reducer前完成排序,因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by只会保证每个reducer的输出有序,并不保证全局有序。sort by不同于order by,它不受hive.mapred.mode属性的影响,sort by的数据只能保证在同一个reduce中的数据可以按指定字段排序。使用sort by你可以指定执行的reduce个数(通过set mapred.reduce.tasks=n来指定),对输出的数据再执行归并排序,即可得到全部结果。
- order by:全局排序,缺陷是只能使用一个 reduce
笛卡尔积
当 Hive 设定为严格模式(hive.mapred.mode=strict)时,不允许在 HQL 语句中出现笛卡尔积, 这实际说明了 Hive 对笛卡尔积支持较弱。因为找不到 Join key,Hive 只能使用 1 个 reducer 来完成笛卡尔积。
当然也可以使用 limit 的办法来减少某个表参与 join 的数据量,但对于需要笛卡尔积语义的 需求来说,经常是一个大表和一个小表的 Join 操作,结果仍然很大(以至于无法用单机处 理),这时 MapJoin才是最好的解决办法。MapJoin,顾名思义,会在 Map 端完成 Join 操作。 这需要将 Join 操作的一个或多个表完全读入内存。
PS:MapJoin 在子查询中可能出现未知 BUG。在大表和小表做笛卡尔积时,规避笛卡尔积的 方法是,给 Join 添加一个 Join key,原理很简单:将小表扩充一列 join key,并将小表的条 目复制数倍,join key 各不相同;将大表扩充一列 join key 为随机数。
精髓就在于复制几倍,最后就有几个 reduce 来做,而且大表的数据是前面小表扩张 key 值 范围里面随机出来的,所以复制了几倍 n,就相当于这个随机范围就有多大 n,那么相应的, 大表的数据就被随机的分为了 n 份。并且最后处理所用的 reduce 数量也是 n,而且也不会 出现数据倾斜。
设置合理的 maptask 数量
Map 数过大
- Map 阶段输出文件太小,产生大量小文件
- 初始化和创建 Map 的开销很大
Map 数太小
- 文件处理或查询并发度小,Job 执行时间过长
- 大量作业时,容易堵塞集群
在 MapReduce 的编程案例中,我们得知,一个MR Job的 MapTask 数量是由输入分片 InputSplit 决定的。而输入分片是由 FileInputFormat.getSplit()决定的。一个输入分片对应一个 MapTask, 而输入分片是由三个参数决定的:
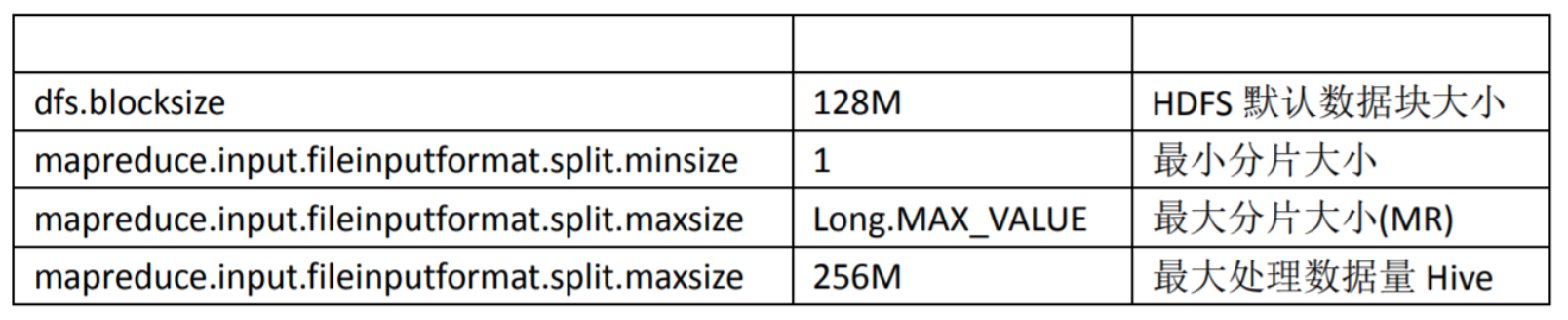
输入分片大小的计算是这么计算出来的:
long splitSize = Math.max(minSize, Math.min(maxSize, blockSize))
默认情况下,输入分片大小和 HDFS 集群默认数据块大小一致,也就是默认一个数据块,启 用一个 MapTask 进行处理,这样做的好处是避免了服务器节点之间的数据传输,提高 job 处 理效率
两种经典的控制 MapTask 的个数方案:减少 MapTask 数或者增加 MapTask 数
- 减少 MapTask 数是通过合并小文件来实现,这一点主要是针对数据源
- 增加 MapTask 数可以通过控制上一个 job 的 reduceTask 个数
因为 Hive 语句最终要转换为一系列的 MapReduce Job 的,而每一个 MapReduce Job 是由一 系列的 MapTask 和 ReduceTask 组成的,默认情况下, MapReduce 中一个 MapTask 或者一个 ReduceTask 就会启动一个 JVM 进程,一个 Task 执行完毕后, JVM 进程就退出。这样如果任 务花费时间很短,又要多次启动 JVM 的情况下,JVM 的启动时间会变成一个比较大的消耗, 这个时候,就可以通过重用 JVM 来解决:
set mapred.job.reuse.jvm.num.tasks=5
小文件合并
件数目过多,会给 HDFS 带来压力,并且会影响处理效率,可以通过合并 Map 和 Reduce 的 结果文件来消除这样的影响:
set hive.merge.mapfiles = true ##在 map only 的任务结束时合并小文件
set hive.merge.mapredfiles = false ## true 时在 MapReduce 的任务结束时合并小文件
set hive.merge.size.per.task = 25610001000 ##合并文件的大小
set mapred.max.split.size=256000000; ##每个 Map 最大分割大小
set mapred.min.split.size.per.node=1; ##一个节点上 split 的最少值
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; ##执行 Map 前进行小文件合并
设置合理的 reduceTask 的数量
Hadoop MapReduce 程序中,reducer 个数的设定极大影响执行效率,这使得 Hive 怎样决定 reducer 个数成为一个关键问题。遗憾的是 Hive 的估计机制很弱,不指定 reducer 个数的情 况下,Hive 会猜测确定一个 reducer 个数,基于以下两个设定:
- hive.exec.reducers.bytes.per.reducer(默认为 256000000)
- hive.exec.reducers.max(默认为 1009)
- mapreduce.job.reduces=-1(设置一个常量 reducetask 数量)
计算 reducer 数的公式很简单: N=min(参数 2,总输入数据量/参数 1) 通常情况下,有必要手动指定 reducer 个数。考虑到 map 阶段的输出数据量通常会比输入有 大幅减少,因此即使不设定 reducer 个数,重设参数 2 还是必要的。
依据 Hadoop 的经验,可以将参数 2 设定为 0.95*(集群中 datanode 个数)。
合并 MapReduce 操作
Multi-group by 是 Hive 的一个非常好的特性,它使得 Hive 中利用中间结果变得非常方便。 例如:
1 | FROM (SELECT a.status, b.school, b.gender FROM status_updates a JOIN profiles b ON (a.userid = |
上述查询语句使用了 multi-group by 特性连续 group by 了 2 次数据,使用不同的 group by key。 这一特性可以减少一次 MapReduce 操作
合理利用分桶:Bucketing 和 Sampling
Bucket 是指将数据以指定列的值为 key 进行 hash,hash 到指定数目的桶中。这样就可以支 持高效采样了。如下例就是以 userid 这一列为 bucket 的依据,共设置 32 个 buckets
1 | CREATE TABLE page_view(viewTime INT, userid BIGINT, |
通常情况下,Sampling 在全体数据上进行采样,这样效率自然就低,它要去访问所有数据。 而如果一个表已经对某一列制作了 bucket,就可以采样所有桶中指定序号的某个桶,这就 减少了访问量。
如下例所示就是采样了 page_view 中 32 个桶中的第三个桶的全部数据:
SELECT * FROM page_view TABLESAMPLE(BUCKET 3 OUT OF 32);
如下例所示就是采样了 page_view 中 32 个桶中的第三个桶的一半数据:
SELECT * FROM page_view TABLESAMPLE(BUCKET 3 OUT OF 64);
合理利用分区:Partition
Partition 就是分区。分区通过在创建表时启用 partitioned by 实现,用来 partition 的维度并不 是实际数据的某一列,具体分区的标志是由插入内容时给定的。当要查询某一分区的内容时 可以采用 where 语句,形似 where tablename.partition_column = a 来实现。
Join 优化
总体原则:
- 优先过滤后再进行 Join 操作,最大限度的减少参与 join 的数据量
- 小表 join 大表,最好启动 mapjoin
- Join on 的条件相同的话,最好放入同一个 job,并且 join 表的排列顺序从小到大
在使用写有 Join 操作的查询语句时有一条原则:应该将条目少的表/子查询放在 Join 操作 符的左边。原因是在 Join 操作的 Reduce 阶段,位于 Join 操作符左边的表的内容会被加 载进内存,将条目少的表放在左边,可以有效减少发生 OOM 错误的几率。对于一条语句 中有多个 Join 的情况,如果 Join 的条件相同,比如查询
1 | INSERT OVERWRITE TABLE pv_users |
如果 Join 的 key 相同,不管有多少个表,都会则会合并为一个 Map-Reduce 任务,而不 是”n”个,在做 OUTER JOIN 的时候也是一样
在编写 Join 查询语句时,如果确定是由于 join 出现的数据倾斜,那么请做如下设置:
1 | set hive.skewjoin.key=100000; // 这个是 join 的键对应的记录条数超过这个值则会进行 分拆,值根据具体数据量设置 |
Group By 优化
- Map 端部分聚合
并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以先在 Map 端进 行部分聚合,最后在 Reduce 端得出最终结果。
MapReduce 的 combiner 组件参数包括:
1 | set hive.map.aggr = true 是否在 Map 端进行聚合,默认为 True |
- 使用 Group By 有数据倾斜的时候进行负载均衡
当 sql 语句使用 groupby 时数据出现倾斜时,如果该变量设置为 true,那么 Hive 会自动进行 负载均衡。策略就是把 MR 任务拆分成两个:第一个先做预汇总,第二个再做最终汇总
在 MR 的第一个阶段中,Map 的输出结果集合会缓存到 maptaks 中,每个 Reduce 做部分聚 合操作,并输出结果,这样处理的结果是相同 Group By Key 有可能被分发到不同的 Reduce 中, 从而达到负载均衡的目的;第二个阶段 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成 最终的聚合操作。
1 | set hive.groupby.skewindata = true |
合理利用文件存储格式
创建表时,尽量使用 orc、parquet 这些列式存储格式,因为列式存储的表,每一列的数据在 物理上是存储在一起的,Hive 查询时会只遍历需要列数据,大大减少处理的数据量
本地模式执行 MapReduce
Hive 在集群上查询时,默认是在集群上 N 台机器上运行, 需要多个机器进行协调运行,这 个方式很好地解决了大数据量的查询问题。但是当 Hive 查询处理的数据量比较小时,其实 没有必要启动分布式模式去执行,因为以分布式方式执行就涉及到跨网络传输、多节点协调 等,并且消耗资源。这个时间可以只使用本地模式来执行 mapreduce job,只在一台机器上 执行,速度会很快。
并行化处理
一个 hive sql 语句可能会转为多个 mapreduce Job,每一个 job 就是一个 stage,这些 job 顺序 执行,这个在 cli 的运行日志中也可以看到。但是有时候这些任务之间并不是是相互依赖的, 如果集群资源允许的话,可以让多个并不相互依赖 stage 并发执行,这样就节约了时间,提 高了执行速度,但是如果集群资源匮乏时,启用并行化反倒是会导致各个 job 相互抢占资源 而导致整体执行性能的下降。启用并行化:
1 | set hive.exec.parallel=true; |
设置压缩存储
Hive 最终是转为 MapReduce 程序来执行的,而 MapReduce 的性能瓶颈在于网络 IO 和 磁盘 IO,要解决性能瓶颈,最主要的是减少数据量,对数据进行压缩是个好的方式。压缩 虽然是减少了数据量,但是压缩过程要消耗 CPU 的,但是在 Hadoop 中, 往往性能瓶颈不 在于 CPU,CPU 压力并不大,所以压缩充分利用了比较空闲的 CPU