Elasticsearch
基本概念
You know, for search (and analysis)
基于Lucene的分布式全文搜索引擎
- 分布式文件存储
- 分布式(准)实时搜索引擎,每个字段都被索引并可被搜索
- 分布式(准)实时分析工具,聚合功能可以构建复杂数据摘要
- 开箱即用。安装好ElasticSearch后,所有参数的默认值都自动进行了比较合理的设置,基本不需要额外的调整。包括内置的发现机制(比如Field类型的自动匹配)和自动化参数配置。
- 天生集群。ElasticSearch默认工作在集群模式下。节点都将视为集群的一部分,而且在启动的过程中自动连接到集群中。
- 自动容错。ElasticSearch通过P2P网络进行通信,这种工作方式消除了单点故障。节点自动连接到集群中的其它机器,自动进行数据交换及以节点之间相互监控。索引分片
- 扩展性强。无论是处理能力和数据容量上都可以通过一种简单的方式实现扩展,即增添新的节点。
- 近实时搜索和版本控制。由于ElasticSearch天生支持分布式,所以延迟和不同节点上数据的短暂性不一致无可避免。ElasticSearch通过版本控制(versioning)的机制尽量减少问题的出现。
分布式
- 节点(Node):一个运行的Elasticearch实例。分为主节点、数据节点、协调节点、部落节点
- 索引(Index),逻辑概念,包括配置信息mapping和倒排正排数据文件
- 分片(Shard):分为主分片和副本分片。索引按某个维度分成多个部分。一个节点(Node)一般会管理来自多个索引的多个分片,同一个索引的分片尽量会分布在不同节点(Node)上。
- 副本(Replica):同一个分片(Shard)的备份数据,分片有>=0个副本。
文件存储
- Index/索引:Index是一类文档的集合,是具有相同业务特征的数据文档集合(不是相同数据结构),相当于传统数据库中的数据库。ES数据的索引、搜索和分析都是基于索引完成的。Cluster中可以创建任意个Index。每个Index(对应Database)包含多个Shard,默认是5个,分散在不同的Node上,但不会存在两个相同的Shard(相同的主和复制)存在一个Node上。当索引创建完成的时候,主分片的数量就固定了,但是复制分片的数量可以随时调整。
- Type/类型:Type是Index中数据的 ,用于标识不同的文档字段信息的集合,相当于传统数据库的表。在0之后的版本直接做了插入检查,禁止一个索引下不同Type的字段类型冲突。举例来说,在一个博客系统中,你可以定义一个 user type,可以定义一个 blog type,还可以定义一个 comment type。
- Document/文档:Document是ES数据可被索引化的基本的存储单元,需要存储在Type中,相当于传统数据库的行记录,使用json来表示。

搜索
- 结构化查询
- 全文搜索
- 嵌套搜索
- 模糊匹配
- 相关度查询
分析
- 时序分析
- 聚合日志
- 数据的可视化
- 数据图谱分析
- 地理位置分析
原理
分布式
主节点作用:
- 主节点上有个单独的进程处理 ClusterState(保存集群的状态,索引/分片的路由表,节点列表,元数据等信息的数据结构)的变更操作,每次变更会更新版本号。变更后会通过PRC接口同步到其他节点。主节知道其他节点的ClusterState 的当前版本,发送变更的时候会做diff,实现增量更新。
- 创建或删除索引
- 跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点
容灾实现:
集群状态:
- 绿色——最健康的状态,代表所有的主分片和副本分片都可用;
- 黄色——所有的主分片可用,但是部分副本分片不可用;
- 红色——部分主分片不可用。
Elasticsearch的恢复流程大致如下:
- 集群中的某个节点丢失网络连接
- master提升该节点上的所有主分片的在其他节点上的副本为主分片cluster
- 集群状态变为 yellow ,因为副本数不够
- 等待一个超时设置的时间,如果丢失节点回来就可以立即恢复(默认为1分钟,通过 index.unassigned.node_left.delayed_timeout 设置)。如果该分片已经有写入,则通过translog进行增量同步数据。
- 否则将副本分配给其他节点,开始同步数据。
选主:
什么时候选主:
- 集群启动
- Master 失效
为什么不用zk/etcd:
es 集群相对较小,而且拓扑结构相对不容易变动。简单场景简单做。
选举原理:
Bully是Leader选举的基本算法之一。 它假定所有节点都有一个惟一的ID,该ID对节点进行排序。 任何时候的当前Leader都是参与集群的最高id节点。 该算法的优点是易于实现,但是,当拥有最大 id 的节点处于不稳定状态的场景下会有问题,例如 Master 负载过重而假死,集群拥有第二大id 的节点被选为 新主,这时原来的 Master 恢复,再次被选为新主,然后又假死
过程:
- 各个节点广播消息,获取集群信息,找出候选节点
- 找到id最小的候选节点,推举为临时master节点
- 选举
- 自认为是临时master的节点开始收集投票
- 自认为不是临时master的节点投票给它认为是临时master的节点临时
- master收集到一定票数时(为防止脑裂,票数阈值一般是 候选节点总数/2+1)变成主节点,开始构建集群
节点间transport层结构:
每个node间维护13个连接,分别负责恢复数据、传输批量请求、传输正常请求、传输状态、ping
分片:
Elasticsearch 的分片默认是基于id 哈希的。
总分片数是不能变动的。副本分片数可以变化。分片切分成本和重新索引的成本差不多,所以建议干脆通过接口重新索引。
每一个分片都是一个单独的Lucene索引。
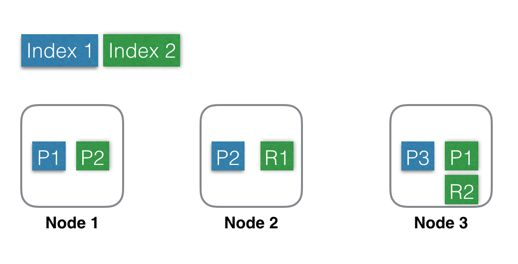
副本分片和主分片不会放在同一个节点内。
每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点,所以也可以将请求转发到需要的节点。举例:索引一个新文档
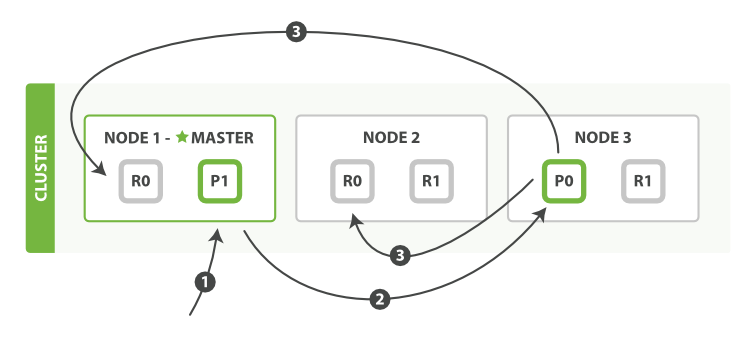
Lucene索引
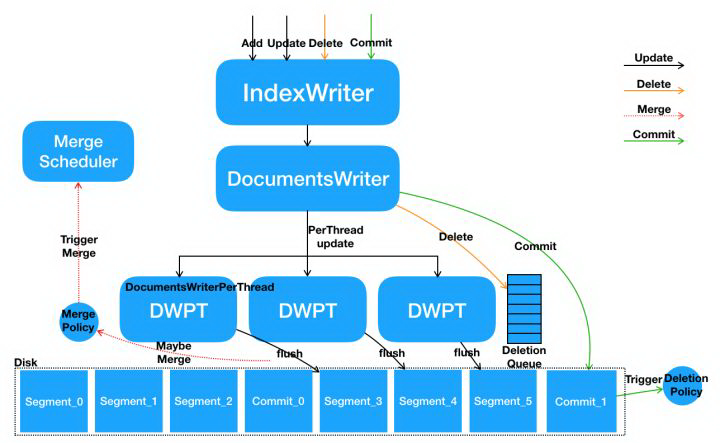
- 多线程并发调用 IndexWriter 的写接口,在 IndexWriter 内部具体请求会由 DocumentsWriter 来执行。DocumentsWriter 内部在处理请求之前,会先根据当前执行操作的 Thread 来分配 DocumentsWriterPerThread。(加锁)
- 每个线程在其独立的 DocumentsWriterPerThread 空间内部进行数据处理,包括分词、相关性计算、索引构建等。
- 数据处理完毕后,在 DocumentsWriter 层面执行一些后续动作,例如触发 FlushPolicy 的判定等。(加锁)
分段存储:
每个索引被分成了多个段(Segment,由域信息(Field information)、词信息(Term information)、以及其它信息(标准化因子、删除文档)组成),段具有一次写入,多次读取的特点。只要形成了,段就无法被修改。例如:被删除文档的信息被存储到一个单独的文件,但是其它的段文件并没有被修改。
索引过程:
[18,20][女,男]叫term
[1,3][2] 叫posting list
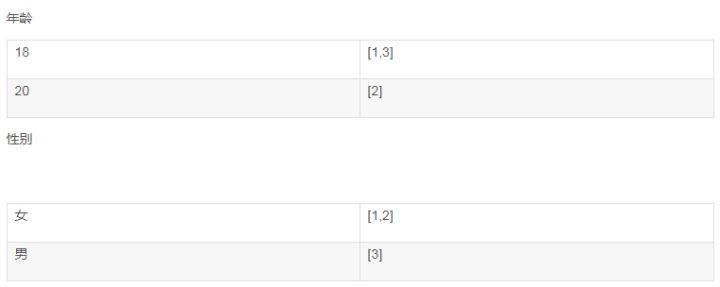
过程:
- Lucene用户指定好的analyzer解析用户添加的Document。当然Document中不同的Field可以指定不同的analyzer。
- term索引
- 字符关键词检索
- term index:树形结构,通过记录term dictionary的某个前缀的offset,然后从这个位置再往后顺序查找。
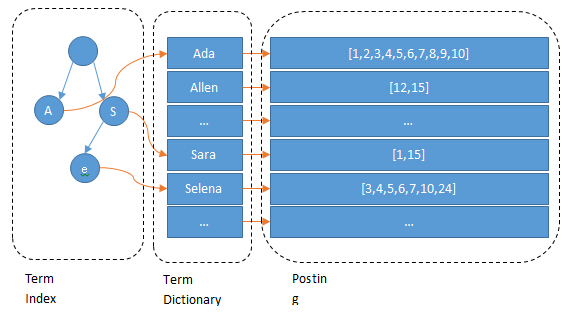
构建Term Dictionary - FST不但能共享前缀还能共享后缀。不但能判断查找的key是否存在,还能给出响应的输入output。 它在时间复杂度和空间复杂度上都做了最大程度的优化,使得Lucene能够将Term Dictionary完全加载到内存,快速的定位Term找到响应的output(posting倒排列表)
%!(EXTRA markdown.ResourceType=, string=, string=)
利用FST(Finite State Transducer,一种类似tire树的有限状态机)压缩term dictionary到内存
- term index:树形结构,通过记录term dictionary的某个前缀的offset,然后从这个位置再往后顺序查找。
- 所以为了支持高效的数值类或者多维度查询,lucene 引入类 BKDTree。BKDTree 是K-D树和 B+ Tree树的结合体,对数据进行按照维度划分建立一棵二叉树确保树两边节点数目平衡。在一维的场景下(一维(如整型字段)、二维(如地理坐标类型字段)),KDTree 就会退化成一个二叉搜索树,在二叉搜索树中如果我们想查找一个区间,logN 的复杂度就会访问到叶子结点得到对应的倒排链。如下图所示:
%!(EXTRA markdown.ResourceType=, string=, string=)
优点:可以局部更新
数值关键词
- 字符关键词检索
- Elasticsearch要求posting list是有序的,有序的posting list可以大大提高搜索速度(特别是面对稀疏索引的场景的时候)。
es利用Frame Of Reference/Roaring bitmaps 压缩posting list,使得其占用更小的空间,同时还可以满足使用使用跳表进行联合索引过滤
posting list索引- 使用(id/65535,id%65535)的格式存储数据
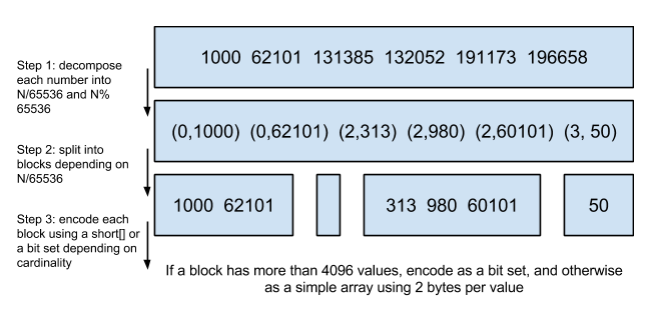
roaring bitmaps - 增量编码压缩,将大数变小数,按字节存储
%!(EXTRA markdown.ResourceType=, string=, string=)
Frame Of Reference
- 使用(id/65535,id%65535)的格式存储数据
Lucene搜索
segment段内搜索
- 用户的输入查询语句将被选定的查询解析器(query parser)所解析,生成多个Query对象。当然用户也可以选择不解析查询语句,使查询语句保留原始的状态。在ElasticSearch中,有的Query对象会被解析(analyzed),有的不会,比如:前缀查询(prefix query)就不会被解析,精确匹配查询(match query)就会被解析。
- term搜索(关键词搜索)
- 为了能够快速查找 docid,lucene 采用了 SkipList 这一数据结构。SkipList 有以下几个特征:
posting list搜索- 元素排序的,对应到我们的倒排链,lucene 是按照 docid 进行排序,从小到大。
- 跳跃有一个固定的间隔,这个是需要建立 SkipList 的时候指定好,例如下图以间隔是 3

SkipList 的层次,这个是指整个 SkipList 有几层
倒排合并
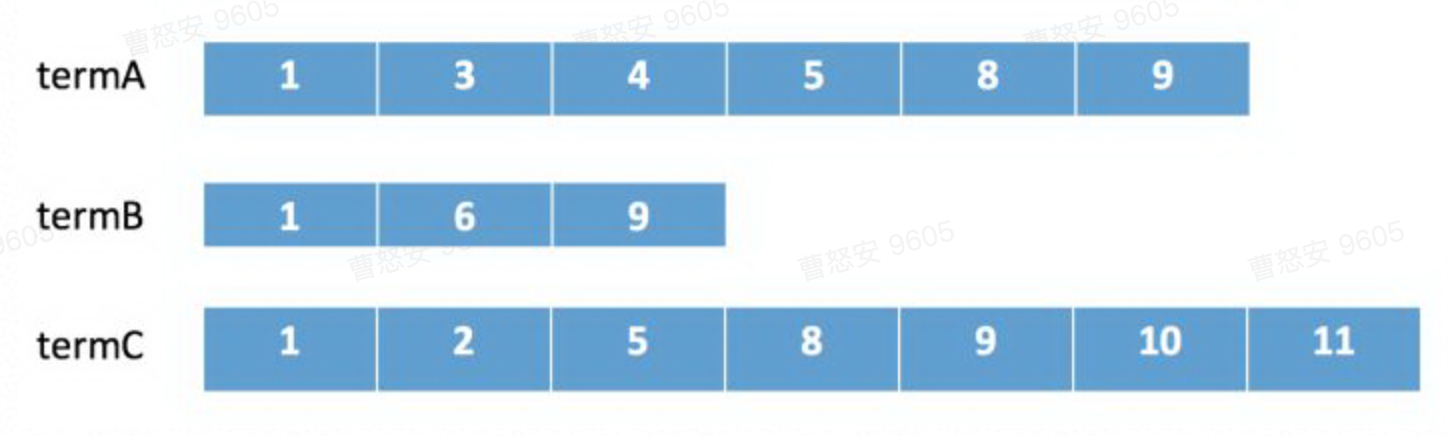
在 lucene 中会采用下列顺序进行合并:
- 在 termA 开始遍历,得到第一个元素 docId=1
- Set currentDocId=1
- 在 termB 中 search(currentDocId) = 1 (返回大于等于 currentDocId 的一个 doc),
- 因为 currentDocId ==1,继续
- 如果 currentDocId 和返回的不相等,执行 2,然后继续
打分
默认是TD-IDF
ES支持重打分。不详细说了
准实时
translog
提供了实时的数据读取能力以及完备的数据持久化能力(在服务器异常挂掉的情况下依然不会丢数据)。Lucene 因为有 IndexWriter buffer, 如果进程异常挂掉,buffer中的数据是会丢失的。所以 Elasticsearch 通过translog来确保不丢数据。同时通过id直接读取文档的时候,Elasticsearch 会先尝试从translog中读取,之后才从索引中读取。也就是说,即便是buffer中的数据尚未刷新到索引,依然能提供实时的数据读取能力。Elasticsearch 的translog 默认是每次写请求完成后统一fsync一次,同时有个定时任务检测(默认5秒钟一次)。如果业务场景需要更大的写吞吐量,可以调整translog相关的配置进行优化。
%!(EXTRA markdown.ResourceType=, string=, string=)
refresh
- 所有在内存缓冲区中的文档被写入到一个新的segment中,但是没有调用fsync,因此内存中的数据可能丢失
- segment被打开使得里面的文档能够被搜索到
- 清空内存缓冲区
%!(EXTRA markdown.ResourceType=, string=, string=)
flush
- 把所有在内存缓冲区中的文档写入到一个新的segment中
- 清空内存缓冲区
- 往磁盘里写入commit point信息
- 文件系统的page cache(segments) fsync到磁盘
- %!(EXTRA markdown.ResourceType=, string=, string=)
删除旧的translog文件,因此此时内存中的segments已经写入到磁盘中,就不需要translog来保障数据安全了
使用场景
常用场景
- 记录和日志分析
- 事件数据和指标
- 数据可视化
- 全文搜索