Hadoop
架构
HDFS
Blocks
物理磁盘中有块的概念,磁盘的物理Block是磁盘操作最小的单元,读写操作均以Block为最小单元,一般为512 Byte。文件系统在物理Block之上抽象了另一层概念,文件系统Block物理磁盘Block的整数倍。通常为几KB。Hadoop提供的df、fsck这类运维工具都是在文件系统的Block级别上进行操作。
HDFS的Block块比一般单机文件系统大得多,默认为128M。HDFS的文件被拆分成block-sized的chunk,chunk作为独立单元存储。比Block小的文件不会占用整个Block,只会占据实际大小。例如, 如果一个文件大小为1M,则在HDFS中只会占用1M的空间,而不是128M。
HDFS的Block为什么这么大?
是为了最小化查找(seek)时间,控制定位文件与传输文件所用的时间比例。假设定位到Block所需的时间为10ms,磁盘传输速度为100M/s。如果要将定位到Block所用时间占传输时间的比例控制1%,则Block大小需要约100M。
但是如果Block设置过大,在MapReduce任务中,Map或者Reduce任务的个数 如果小于集群机器数量,会使得作业运行效率很低。
Block抽象的好处
block的拆分使得单个文件大小可以大于整个磁盘的容量,构成文件的Block可以分布在整个集群, 理论上,单个文件可以占据集群中所有机器的磁盘。
Block的抽象也简化了存储系统,对于Block,无需关注其权限,所有者等内容(这些内容都在文件级别上进行控制)。
Block作为容错和高可用机制中的副本单元,即以Block为单位进行复制。
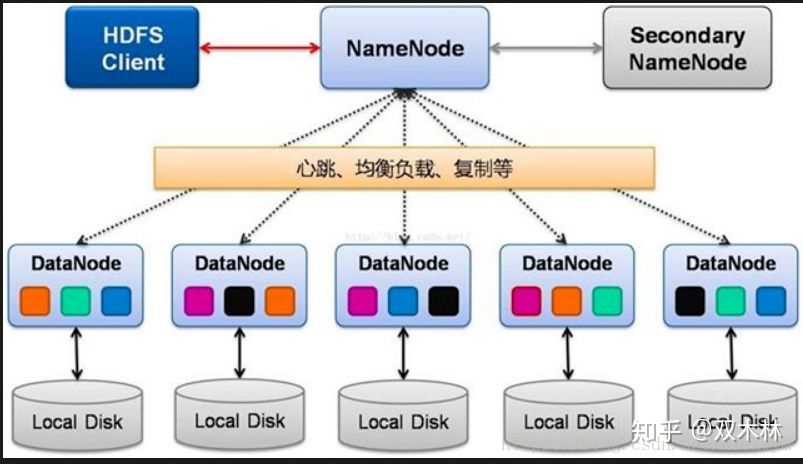
NameNode
NameNode也叫名称节点,它管理文件系统的命名空间,维护着文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:
- 命名空间镜像文件(namespcae image)
- 编辑日志文件(edit log)
对整个分布式文件系统进行总控制,会纪录所有的元数据分布存储的状态信息。比如文件是如何分割成数据块的,以及这些数据块被存储到哪些节点上,还有对内存和I/O进行集中管理。但是持久化数据中不包括Block所在的节点列表,及文件的Block分布在集群中的哪些节点上,这些信息是在系统重启的时候重新构建(通过Datanode汇报的Block信息)。用户首先会访问Namenode,获取文件分布的状态信息,然后访问相应的节点,把文件拿到。
整个HDFS可存储的文件数受限于NameNode的内存大小。
不过这是个单点,如果NameNode宕机,那么整个集群就瘫痪了。
Secondary Namenode
Secondary NameNode,该部分主要是定时对NameNode数据进行备份,这样尽量降低NameNode崩溃之后,导致数据的丢失,其实所作的工作就是从NameNode获得fsimage(命名空间镜像文件)和edits(编辑日志文件)把二者重新合并然后发给NameNode,这样,既能减轻NameNode的负担又能保险地备份。
DataNode
数据节点,提供真实文件数据的存储服务。每台从服务器节点都运行一个,负责把HDFS数据块读、写到本地文件系统。
文件写入
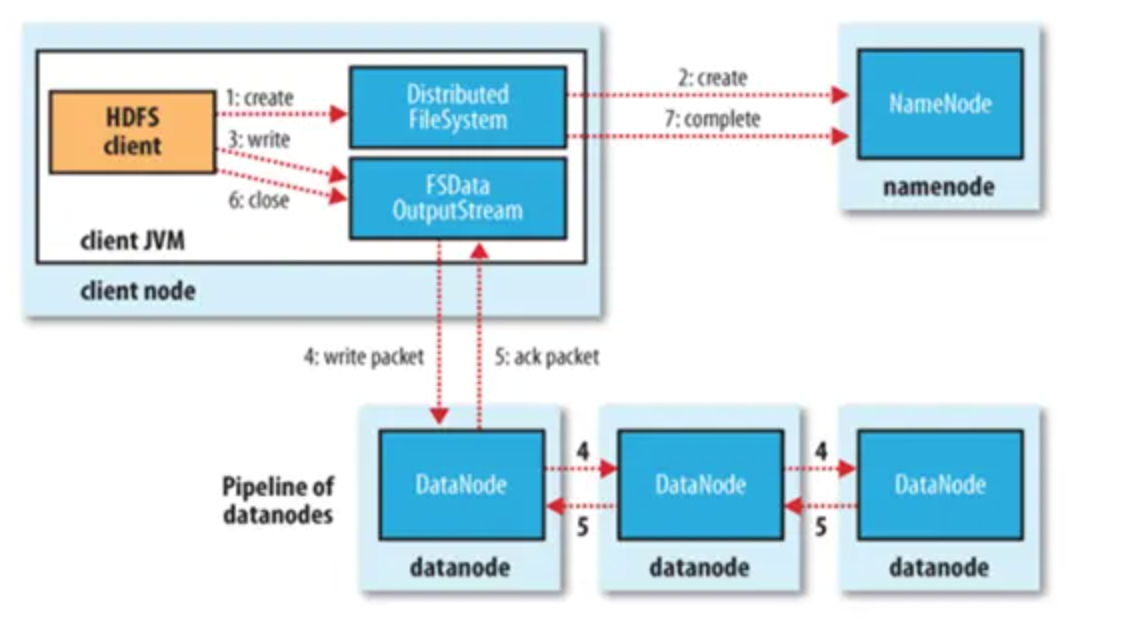
- Client向NameNode发起文件写入的请求
- NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
- Client将文件划分为多个文件块,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
文件读取
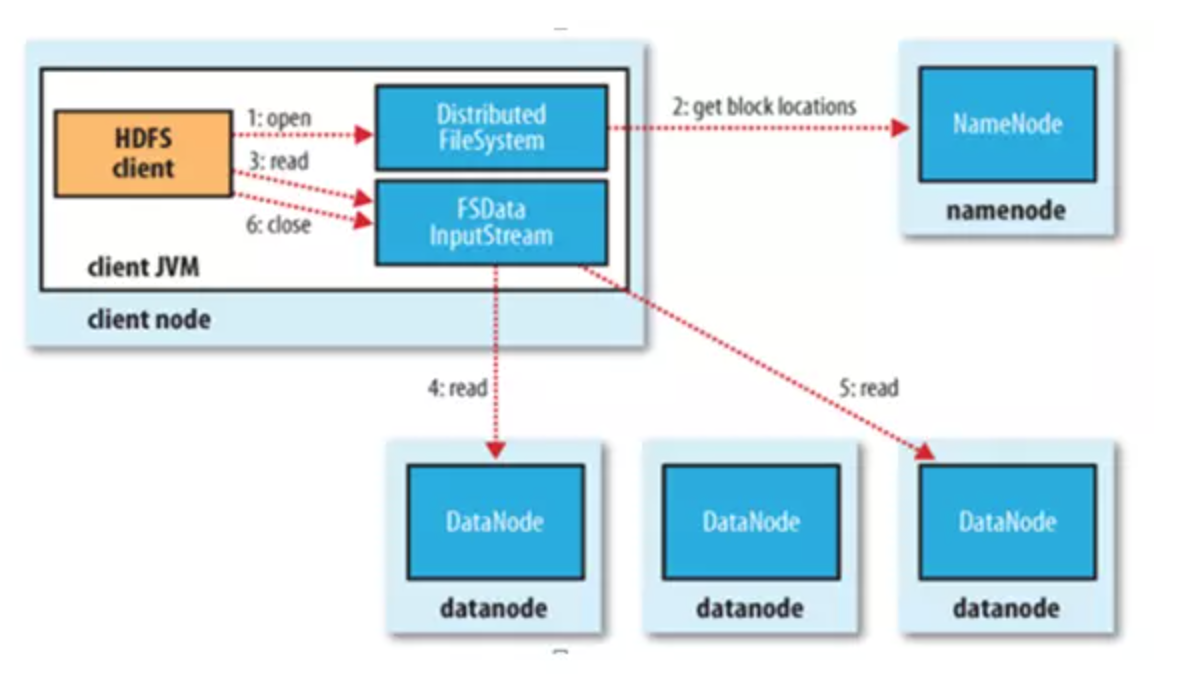
- Client向NameNode发起文件读取的请求
- NameNode返回文件存储的DataNode的信息。
- Client读取文件信息。
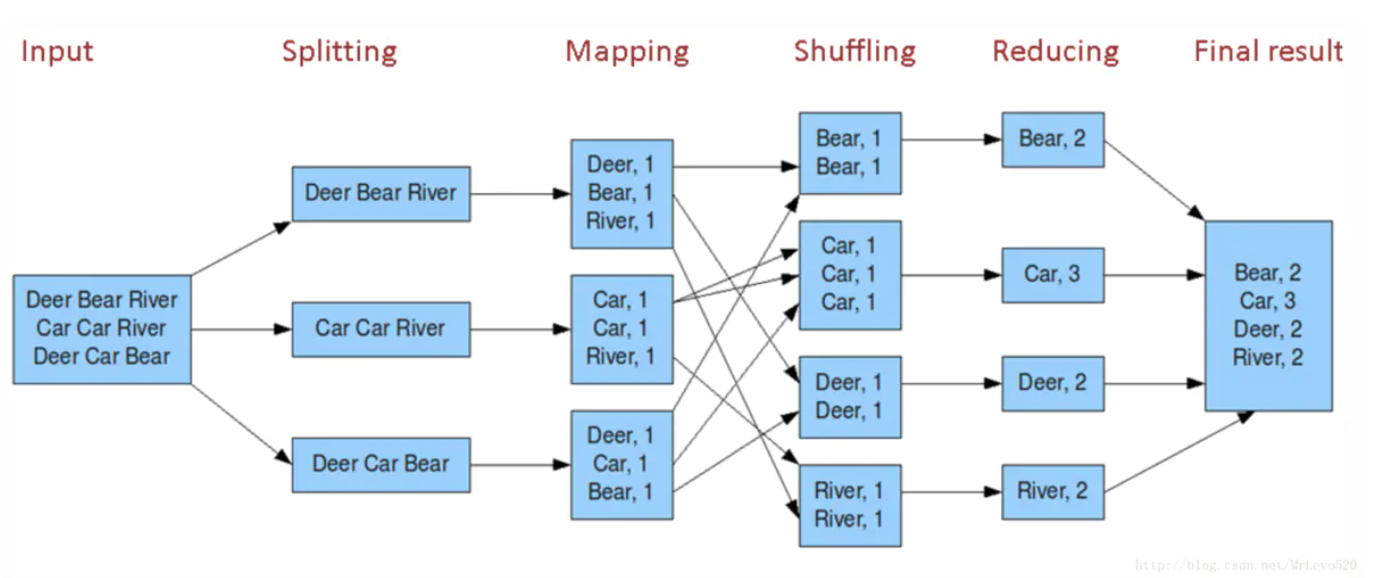
MapReduce
MapReduce是一种编程模型,用于大规模数据集的并行运算。Map(映射)和Reduce(化简),采用分而治之思想,先把任务分发到集群多个节点上,并行计算,然后再把计算结果合并,从而得到最终计算结果。多节点计算,所涉及的任务调度、负载均衡、容错处理等,都由MapReduce框架完成,不需要编程人员关心这些内容。
1.0
MapReduce采用Master/Slave结构。
- Master:是整个集群的唯一的全局管理者,功能包括:作业管理、状态监控和任务调度等,即MapReduce中的JobTracker。
- Slave:负责任务的执行和任务状态的回报,即MapReduce中的TaskTracker。
JobTracker
作业跟踪器,运行在主节点(Namenode)上的一个很重要的进程,是MapReduce体系的调度器。用于处理作业(用户提交的代码)的后台程序,决定有哪些文件参与作业的处理,然后把作业切割成为一个个的小task,并把它们分配到所需要的数据所在的子节点。(程序跟着数据跑,这样子就可以避免对数据进行重新分配)
TaskTracker
任务跟踪器,运行在每个slave节点上,与datanode结合(代码与数据一起的原则),管理各自节点上的task(由jobtracker分配),每个节点只有一个tasktracker,但一个tasktracker可以启动多个JVM,用于并行执行map或reduce任务,它与jobtracker交互通信,可以告知jobtracker子任务完成情况。
两者联系:JobTracker会给TaskTracker下达各种命令,主要包括:启动任务(LaunchTaskAction)、提交任务(CommitTaskAction)、杀死任务(KillTaskAction)、杀死作业(KillJobAction)和重新初始化(TaskTrackerReinitAction)。
2.0
Yarn
HA
MapReduce流程

Map阶段
- 读取输入文件的内容,并解析成键值对(<key, value>)的形式,输入文件中的每一行被解析成一个<key, value>对,每个<key, value>对调用一次map()函数。
- 用户写map()函数,对输入的<key,value>对进行处理,并输出新的<key,value>对。
3。 对Step 2中得到的<key,value>进行分区操作。 - 不同分区的数据,按照key值进行排序和分组,具有相同key值的value则放到同一个集合中。
- 分组后的数据进行规约。
Shuffle
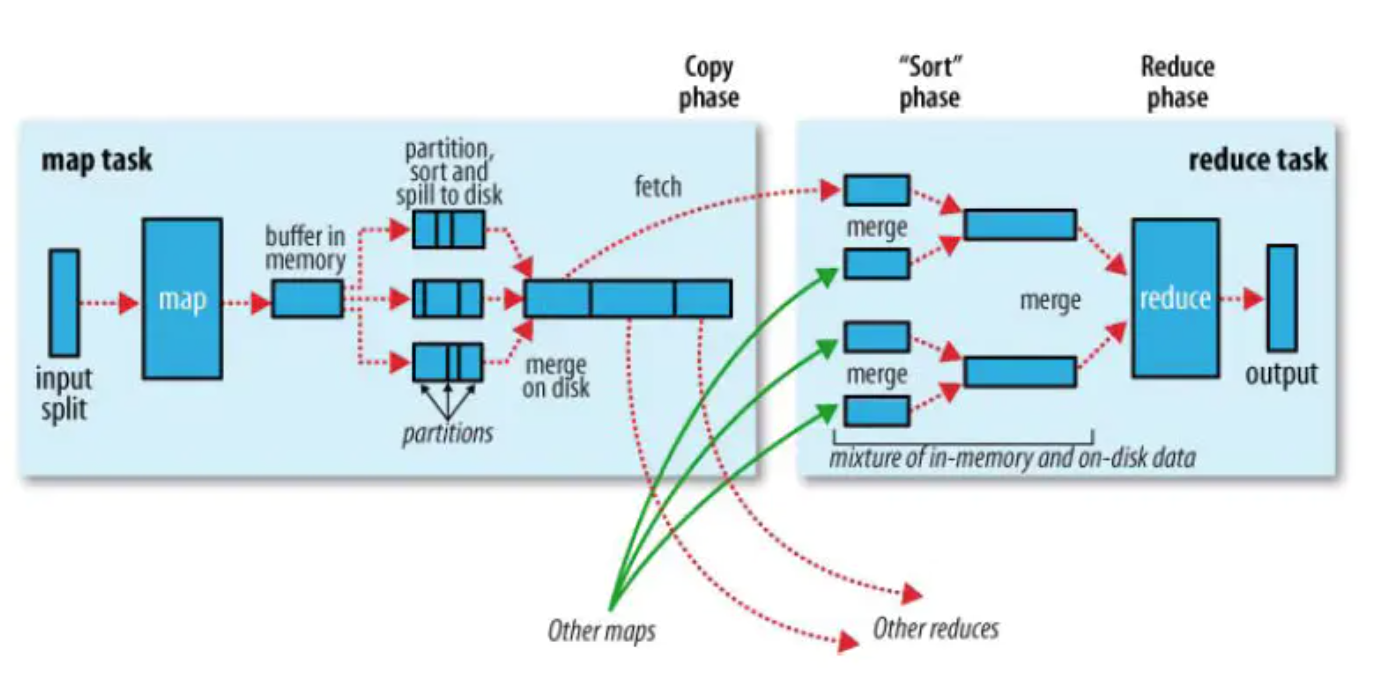
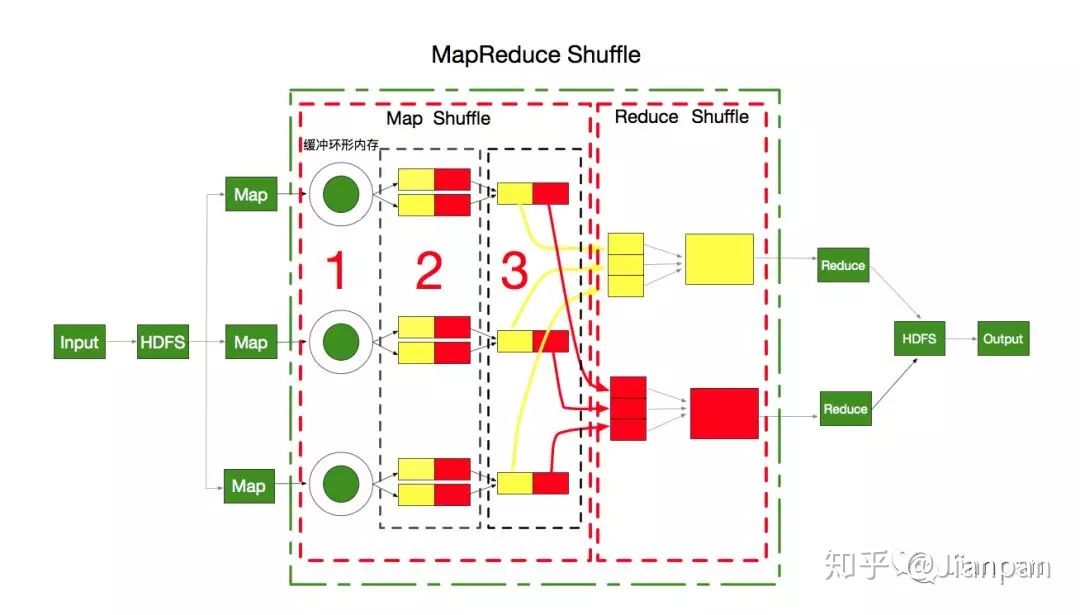

Map Shuffle
- 环形内存缓存区:每个split数据交由一个map任务处理,map的处理结果不会直接写到硬盘上,会先输送到环形内存缓存区中,默认的大小是100M(可通过配置修改),当缓冲区的内容达到80%后会开始溢出,此时缓存区的溢出内容会被写到磁盘上,形成一个个spill file,注意这个文件没有固定大小。
- 在内存中经过分区、排序后溢出到磁盘:分区主要功能是用来指定 map 的输出结果交给哪个 reduce 任务处理,默认是通过 map 输出结果的 key 值取hashcode 对代码中配置的 redue task数量取模运算,值一样的分到一个区,也就是一个 reduce 任务对应一个分区的数据。这样做的好处就是可以避免有的 reduce 任务分配到大量的数据,而有的 reduce 任务只分配到少量甚至没有数据,平均 reduce 的处理能力。并且在每一个分区(partition)中,都会有一个 sort by key 排序,如果此时设置了 Combiner,将排序后的结果进行 Combine 操作,相当于 map 阶段的本地 reduce,这样做的目的是让尽可能少的数据写入到磁盘。
- 合并溢出文件:随着 map 任务的执行,不断溢出文件,直到输出最后一个记录,可能会产生大量的溢出文件,这时需要对这些大量的溢出文件进行合并,在合并文件的过程中会不断的进行排序跟 Combine 操作,这样做有两个好处:减少每次写入磁盘的数据量&减少下一步 reduce 阶段网络传输的数据量。最后合并成了一个分区且排序的大文件,此时可以再进行配置压缩处理,可以减少不同节点间的网络传输量。合并完成后着手将数据拷贝给相对应的reduce 处理,那么要怎么找到分区数据对应的那个 reduce 任务呢?简单来说就是 JobTracker 中保存了整个集群中的宏观信息,只要 reduce 任务向 JobTracker 获取对应的 map 输出位置就可以了。具体请参考上方的MapReduce工作原理。
Reduce Shuffle
reduce 会接收到不同 map 任务传来的有序数据,如果 reduce 接收到的数据较小,则会存在内存缓冲区中,直到数据量达到该缓存区的一定比例时对数据进行合并后溢写到磁盘上。随着溢写的文件越来越多,后台的线程会将他们合并成一个更大的有序的文件,可以为后面合并节省时间。这其实跟 map端的操作一样,都是反复的进行排序、合并,这也是 Hadoop 的灵魂所在,但是如果在 map 已经压缩过,在合并排序之前要先进行解压缩。合并的过程会产生很多中间文件,但是最后一个合并的结果是不需要写到磁盘上,而是可以直接输入到 reduce 函数中计算,每个 reduce 对应一个输出结果文件。
Reduce阶段
- 对于多个map任务的输出,按照不同的分区,通过网络传输到不同的Reduce节点。
- 对多个map任务的输出结果进行合并、排序,用户书写reduce函数,对输入的key、value进行处理,得到新的key、value输出结果。
- 将reduce的输出结果保存在文件中。
例子