文件类型
普通文件
从Linux的角度来说,类似mp4、pdf、html这样应用层面上的文件类型都属于普通文件Linux用户可以根据访问权限对普通文件进行查看、更改和删除
目录文件(d,directory file)
目录文件对于用惯Windows的用户来说不太容易理解,目录也是文件的一种目录文件包含了各自目录下的文件名和指向这些文件的指针,打开目录事实上就是打开目录文件,只要有访问权限,你就可以随意访问这些目录下的文件(普通文件的执行权限就是目录文件的访问权限),但是只有内核的进程能够修改它们虽然不能修改,但是我们能够通过vim去查看目录文件的内容
符号链接(l,symbolic link)
这种类型的文件类似Windows中的快捷方式,是指向另一个文件的间接指针,也就是我们常说的软链接
块设备文件(b,block)和字符设备文件(c,char)
这些文件一般隐藏在/dev目录下,在进行设备读取和外设交互时会被使用到比如磁盘光驱就是块设备文件,串口设备则属于字符设备文件系统中的所有设备要么是块设备文件,要么是字符设备文件,无一例外
FIFO(p,pipe)
管道文件主要用于进程间通讯。比如使用mkfifo命令可以创建一个FIFO文件,启用一个进程A从FIFO文件里读数据,启动进程B往FIFO里写数据,先进先出,随写随读。
套接字(s,socket)
用于进程间的网络通信,也可以用于本机之间的非网络通信这些文件一般隐藏在/var/run目录下,证明着相关进程的存在
Linux 的文件是没有所谓的扩展名的,一个 Linux文件能不能被执行与它是否可执行的属性有关,只要你的权限中有 x ,比如[ -rwx-r-xr-x ] 就代表这个文件可以被执行,与文件名没有关系。跟在 Windows下能被执行的文件扩展名通常是 .com .exe .bat 等不同。不过,可以被执行跟可以执行成功不一样。比如在 root 主目彔下的 install.log 是一个文本文件,修改权限成为 -rwxrwxrwx 后这个文件能够真的执行成功吗? 当然不行,因为它的内容根本就没有可以执行的数据。所以说,这个 x 代表这个文件具有可执行的能力, 但是能不能执行成功,当然就得要看该文件的内容了。虽然如此,不过我们仍然希望能从扩展名来了解该文件是什么东西,所以一般我们还是会以适当的扩展名来表示该文件是什么种类的。所以Linux 系统上的文件名真的只是让你了解该文件可能的用途而已, 真正的执行与否仍然需要权限的规范才行。比如常见的/bin/ls 这个显示文件属性的指令要是权限被修改为无法执行,那么ls 就变成不能执行了。这种问题最常发生在文件传送的过程中。例如你在网络上下载一个可执行文件,但是偏偏在你的 Linux 系统中就是无法执行,那就可能是档案的属性被改变了。而且从网络上传送到你 的 Linux 系统中,文件的属性权限确实是会被改变的
文件描述符
文件描述符、文件、进程间的关系
- 每个文件描述符会与一个打开的文件相对应
- 不同的文件描述符也可能指向同一个文件
- 相同的文件可以被不同的进程打开,也可以在同一个进程被多次打开
系统为维护文件描述符,建立了三个表
- 进程级的文件描述符表
- 系统级的文件描述符表
- 文件系统的i-node表
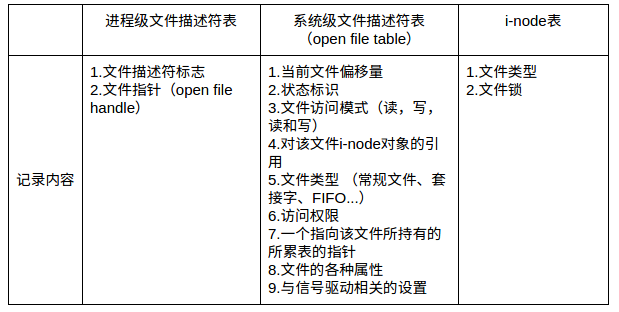
示例:
%!(EXTRA markdown.ResourceType=, string=, string=)
- 在进程A中,文件描述符1和30都指向了同一个打开的文件句柄(#23),这可能是该进程多次对执行打开操作
- 进程A中的文件描述符2和进程B的文件描述符2都指向了同一个打开的文件句柄(#73),这种情况有几种可能,
- 进程A和进程B可能是父子进程关系;
- 进程A和进程B打开了同一个文件,且文件描述符相同(低概率事件);
- A、B中某个进程通过UNIX域套接字将一个打开的文件描述符传递给另一个进程。
- 进程A的描述符0和进程B的描述符3分别指向不同的打开文件句柄,但这些句柄均指向i-node表的相同条目(#1936),换言之,指向同一个文件。发生这种情况是因为每个进程各自对同一个文件发起了打开请求。同一个进程两次打开同一个文件,也会发生类似情况。
文件描述符限制
格式
Linux操作系统支持很多不同的文件系统,比如ext2、ext3、XFS、FAT等等,而Linux把对不同文件系统的访问交给了VFS(虚拟文件系统),VFS能访问和管理各种不同的文件系统。所以有了区之后就需要把它格式化成具体的文件系统以便VFS访问。
标准的Linux文件系统Ext2是使用「基于inode的文件系统」
一般操作系统的文件数据除了文件实际内容外, 还带有很多属性,例如 Linux 操作系统的文件权限(rwx)与文件属性(拥有者、群组、 时间参数等),文件系统通常会将属性和实际内容这两部分数据分别存放在不同的区块在基于inode的文件系统中,权限与属性放置到 inode 中,实际数据放到 data block 区块中,而且inode和data block都有编号Ext2 文件系统在此基础上
文件系统最前面有一个启动扇区(boot sector)这个启动扇区可以安装开机管理程序, 这个设计让我们能将不同的引导装载程序安装到个别的文件系统前端,而不用覆盖整个硬盘唯一的MBR, 也就是这样才能实现多重引导的功能把每个区进一步分为多个块组 (block group),每个块组有独立的inode/block体系如果文件系统高达数百 GB 时,把所有的 inode 和block 通通放在一起会因为 inode 和 block的数量太庞大,不容易管理这其实很好理解,因为分区是用户的分区,实际计算机管理时还有个最适合的大小,于是计算机会进一步的在分区中分块(但这样岂不是可能出现大文件放不了的问题?有什么机制善后吗?)每个块组实际还会分为分为6个部分,除了inode table 和 data block外还有4个附属模块,起到优化和完善系统性能的作用所以整个分区大概会这样划分:
- inode table
主要记录文件的属性以及该文件实际数据是放置在哪些block中,它记录的信息至少有这些:大小、真正内容的block号码(一个或多个)访问模式(read/write/excute)拥有者与群组(owner/group)各种时间:建立或状态改变的时间、最近一次的读取时间、最近修改的时间没有文件名!文件名在目录的block中!一个文件占用一个 inode,每个inode有编号Linux 系统存在 inode 号被用完但磁盘空间还有剩余的情况注意,这里的文件不单单是普通文件,目录文件也就是文件夹其实也是一个文件,还有其他的也是inode 的数量与大小在格式化时就已经固定了,每个inode 大小均固定为128 bytes (新的ext4 与xfs 可设定到256 bytes)文件系统能够建立的文件数量与inode 的数量有关,存在空间还够但inode不够的情况系统读取文件时需要先找到inode,并分析inode 所记录的权限与使用者是否符合,若符合才能够开始实际读取 block 的内容inode 要记录的资料非常多,但偏偏又只有128bytes , 而inode 记录一个block 号码要花掉4byte ,假设我一个文件有400MB 且每个block 为4K 时, 那么至少也要十万条block 号码的记录!inode 哪有这么多空间来存储?为此我们的系统很聪明的将inode 记录block 号码的区域定义为12个直接,一个间接, 一个双间接与一个三间接记录区(详细见附录) - data block
放置文件内容数据的地方在格式化时block的大小就固定了,且每个block都有编号,以方便inode的记录原则上,block 的大小与数量在格式化完就不能够再改变了(除非重新格式化)在Ext2文件系统中所支持的block大小有1K, 2K及4K三种,由于block大小的区别,会导致该文件系统能够支持的最大磁盘容量与最大单一文件容量各不相同:Block 大小 1KB 2KB 4KB最大单一档案限制 16GB 256GB 2TB最大档案系统总容量 2TB 8TB 16TB每个block 内最多只能够放置一个文件的资料,但一个文件可以放在多个block中(大的话)若文件小于block ,则该block 的剩余容量就不能够再被使用了(磁盘空间会浪费)所以如果你的档案都非常小,但是你的block 在格式化时却选用最大的4K 时,可能会产生容量的浪费既然大的block 可能会产生较严重的磁碟容量浪费,那么我们是否就将block 大小定为1K ?这也不妥,因为如果block 较小的话,那么大型档案将会占用数量更多的block ,而inode 也要记录更多的block 号码,此时将可能导致档案系统不良的读写效能事实上现在的磁盘容量都太大了,所以一般都会选择4K 的block 大小 - superblock
记录整个文件系统相关信息的地方,一般大小为1024bytes,记录的信息主要有:block 与inode 的总量未使用与已使用的inode / block 数量一个valid bit 数值,若此文件系统已被挂载,则valid bit 为0 ,若未被挂载,则valid bit 为1block 与inode 的大小 (block 为1, 2, 4K,inode 为128bytes 或256bytes);其他各种文件系统相关信息:filesystem 的挂载时间、最近一次写入资料的时间、最近一次检验磁碟(fsck) 的时间Superblock是非常重要的, 没有Superblock ,就没有这个文件系统了,因此如果superblock死掉了,你的文件系统可能就需要花费很多时间去挽救每个块都可能含有superblock,但是我们也说一个文件系统应该仅有一个superblock 而已,那是怎么回事?事实上除了第一个块内会含有superblock 之外,后续的块不一定含有superblock,而若含有superblock则该superblock主要是做为第一个块内superblock的备份,这样可以进行superblock的救援 - Filesystem Description
文件系统描述这个区段可以描述每个block group的开始与结束的block号码,以及说明每个区段(superblock, bitmap, inodemap, data block)分别介于哪一个block号码之间 - block bitmap
块对照表如果你想要新增文件时要使用哪个block 来记录呢?当然是选择「空的block」来记录。那你怎么知道哪个block 是空的?这就得要通过block bitmap了,它会记录哪些block是空的,因此我们的系统就能够很快速的找到可使用的空间来记录同样在你删除某些文件时,那些文件原本占用的block号码就得要释放出来, 此时在block bitmap 中对应该block号码的标志位就得要修改成为「未使用中」 - inode bitmap
与block bitmap 是类似的功能,只是block bitmap 记录的是使用与未使用的block 号码, 至于inode bitmap 则是记录使用与未使用的inode 号码
流程
创建文件过程
当在ext2下建立一个一般文件时, ext2 会分配一个inode 与相对于该文件大小的block 数量给该文件
- 例如:假设我的一个block 为4 Kbytes ,而我要建立一个100 KBytes 的文件,那么linux 将分配一个inode 与25 个block 来储存该文件
- 但同时请注意,由于inode 仅有12 个直接指向,因此还要多一个block 来作为区块号码的记录
创建目录过程
当在ext2文件系统建立一个目录时(就是新建了一个目录文件),文件系统会分配一个inode与至少一块block给该目录
- inode记录该目录的相关权限与属性,并记录分配到的那块block号码
- 而block则是记录在这个目录下的文件名与该文件对应的inode号
- block中还会自动生成两条记录,一条是.文件夹记录,inode指向自身,另一条是..文件夹记录,inode指向父文件夹
从目录树中读取某个文件过程
因为文件名是记录在目录的block当中,因此当我们要读取某个文件时,就一定会经过目录的inode与block ,然后才能够找到那个待读取文件的inode号码,最终才会读到正确的文件的block内的资料。
由于目录树是由根目录开始,因此操作系统先通过挂载信息找到挂载点的inode号,由此得到根目录的inode内容,并依据该inode读取根目录的block信息,再一层一层的往下读到正确的文件。举例来说,如果我想要读取/etc/passwd 这个文件时,系统是如何读取的呢?先看一下这个文件以及有关路径文件夹的信息:
1$ ll -di / /etc /etc/passwd2 128 dr-xr-x r-x . 17 root root 4096 May 4 17:56 /333595521 drwxr-x r-x . 131 root root 8192 Jun 17 00:20 /etc436628004 -rw-r– r– . 1 root root 2092 Jun 17 00:20 /etc/passwd复制代码
于是该文件的读取流程为:
- /的inode:通过挂载点的信息找到inode号码为128的根目录inode,且inode规定的权限让我们可以读取该block的内容(有r与x)
- /的block:经过上个步骤取得block的号码,并找到该内容有etc/目录的inode号码(33595521)
- etc/的inode:读取33595521号inode得知具有r与x的权限,因此可以读取etc/的block内容
- etc/的block:经过上个步骤取得block号码,并找到该内容有passwd文件的inode号码(36628004)
- passwd的inode:读取36628004号inode得知具有r的权限,因此可以读取passwd的block内容
- passwd的block:最后将该block内容的资料读出来