Yarn
背景
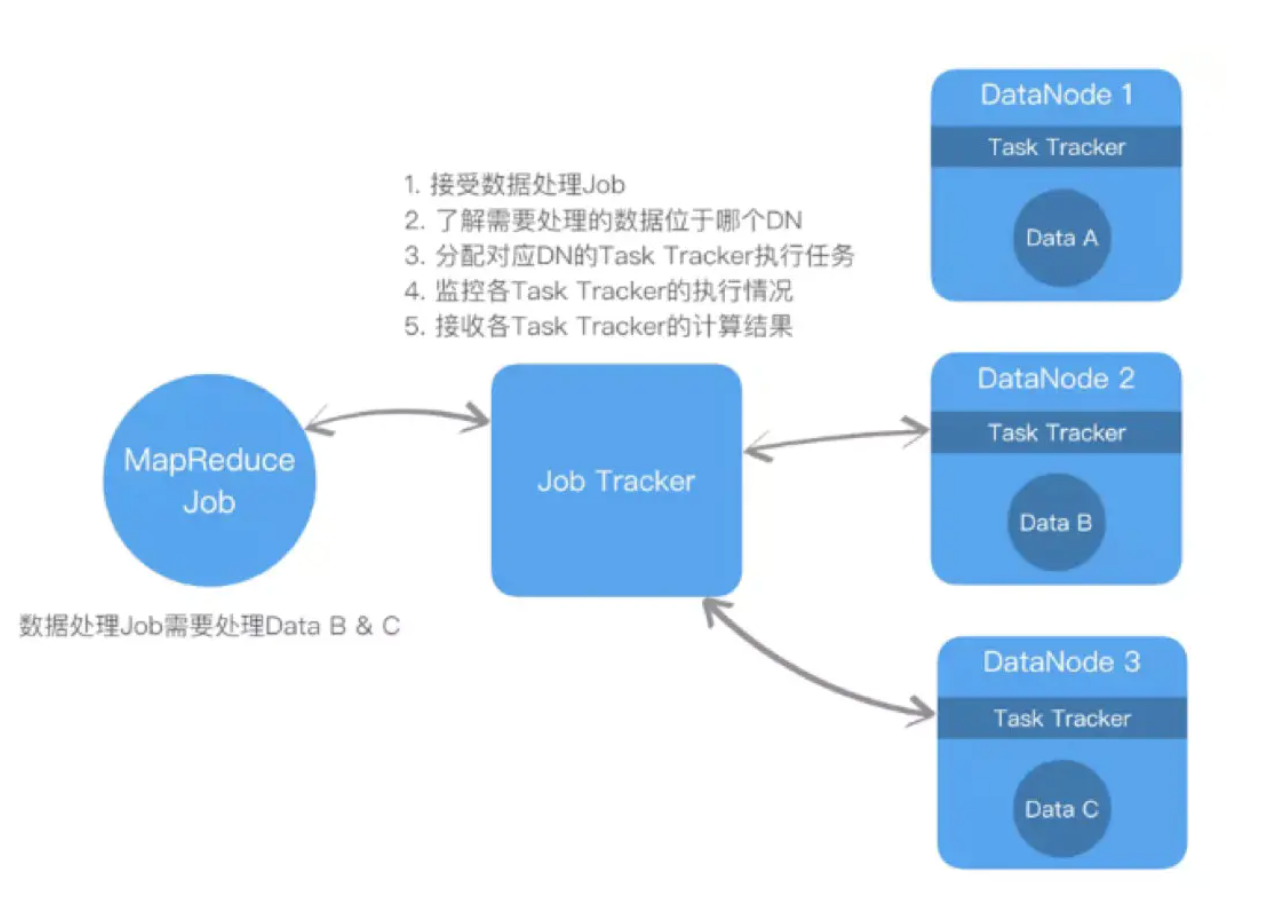
hadoop1.0中架构:
问题:
- 由于大量的数据处理Job提交给Job Tracker,且Job Tracker需要协调的Data Node可能有数千台,Job Tracker极易成为整个系统的性能、可用的瓶颈。
- 无法有效地调配资源,导致资源分配不均。如以下例子,假设有3台Data Node(DN),每个DN的内存为4GB。用户提交了6个Job,每个Job需要1GB内存进行处理,且数据均在DN2上。由于DN2只有4GB内存,所以Job1-4在DN2上运行,Job5和6则在排队等待。但是,此时DN1和3均在闲置的状态下,而未能有效的被利用。
模块
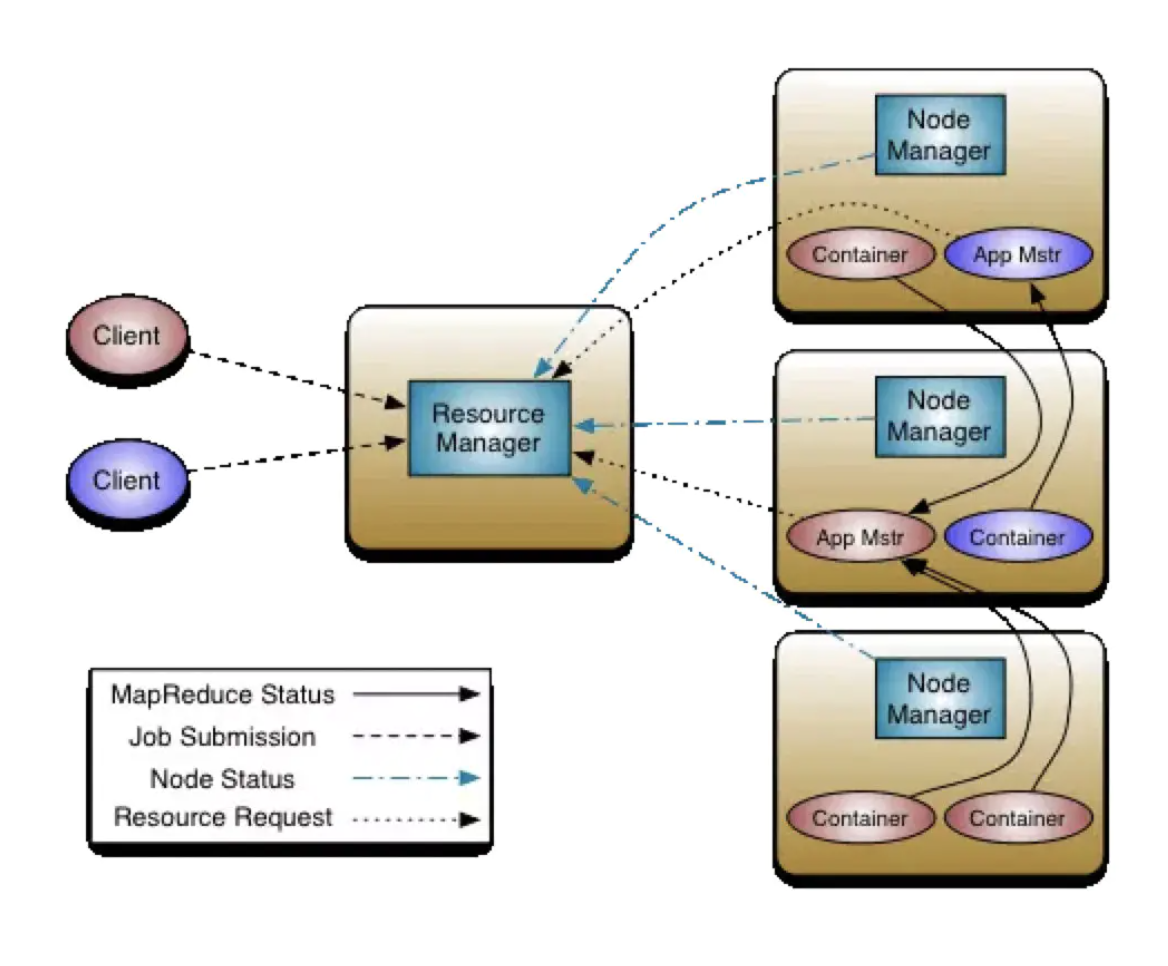
ResourceManager
负责对各个NodeManager 上的资源进行统一管理和调度。包含两个组件:
- Scheduler:调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序
- Applications Manager:应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等
NodeManager
NM 是每个节点上的资源和任务管理器。
- 定时地向RM 汇报本节点上的资源使用情况和各个Container 的运行状态
- 接收并处理来自AM 的Container启动/ 停止等各种请求
ApplicationMaster
用户提交的每个应用程序均包含一个AM,主要功能包括:
- 与RM 调度器协商以获取资源(用 Container 表示)
- 将得到的任务进一步分配给内部的任务
- 与 NM 通信以启动 / 停止任务
- 监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务
Container
Container 是YARN 中的资源抽象, 它封装了某个节点上的多维度资源, 如内存、CPU、磁盘、网络等,当AM 向RM 申请资源时,RM 为AM 返回的资源便是用Container表示的
工作流程
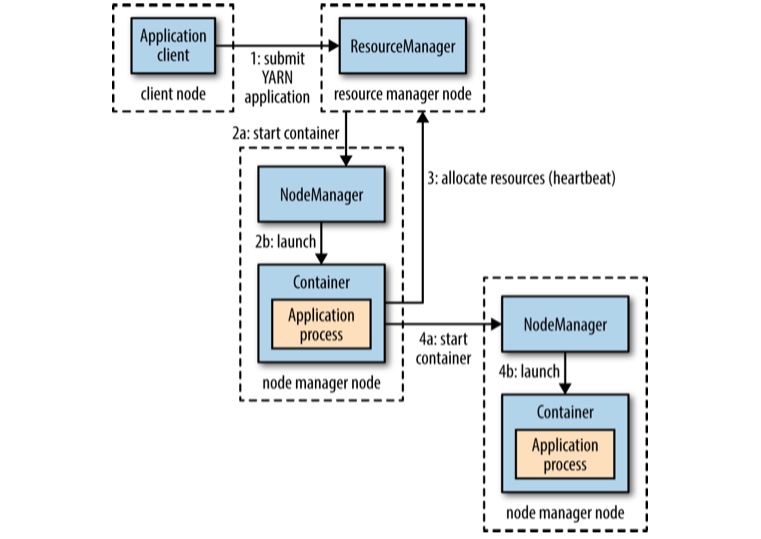
- 用户向YARN 中提交应用程序, 其中包括ApplicationMaster 程序、启动ApplicationMaster 的命令、用户程序等。
- ResourceManager 为该应用程序分配第一个Container,并与对应的Node-Manager 通信,要求它在这个Container中启动应用程序的ApplicationMaster。
- ApplicationMaster 首先向ResourceManager 注册,这样用户可以直接通过ResourceManage 查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
- ApplicationMaster 采用轮询的方式通过RPC 协议向ResourceManager 申请和领取资源。
- 一旦ApplicationMaster 申请到资源后,便与对应的NodeManager 通信,要求它启动任务。
- NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 各个任务通过某个RPC 协议向ApplicationMaster 汇报自己的状态和进度,以让ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster 查询应用程序的当前运行状态。
- 应用程序运行完成后,ApplicationMaster 向ResourceManager 注销并关闭自己。
资源调度算法
FIFO
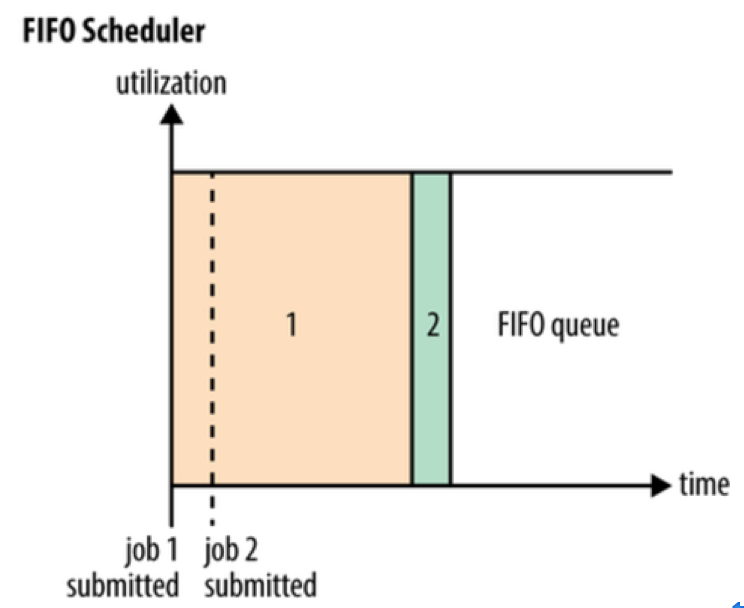
FIFO 调度算法用于最早的 Hadoop 系统中,Hadoop 面向的是单用户提交的大规模数据处理作业。在 FIFO 调度算法中只有一个用户,所有作业按照优先级提交至具有不同优先级的队列中,然后由调度器(Scheduler)先按照作业提交的时间顺序选择待执行的作业。FIFO 的队列设置了 5 个优先等级,分别为:Very Low、Low、Normal、High 及 Very High。每个等级对应一个队列,按照队列的优先级从高到低选取队列,在同级队列中,按照提交作业的时间先后顺序提取并执行。其调度大体流程如图所示。
Capacity 调度算法
- 队列中单个任务使用的资源不会超过队列的容量。
- 如果队列满,且集群有空闲的资源,调度器可以把资源分配给此队列(可配置),弹性队列。
- 正常情况下,容量调度器不会抢占容器,因此如果一个队列随着使用,资源不够时,只能等待其他队列释放资源。
- 容量调度器也可以执行work-preserving preemption,RM会请求应用返回容器。
Capacity 调度算法是由 Yahoo!开发的多用户调度策略,它以队列为单位划分资源,每个队列可设定一定比例的资源最低保证和使用上限,同时每个用户也可设定一定的资源使用上限以防止资源滥用。而当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。Capacity Scheduler 支持多个队列,每个队列可分配一定的资源量,队列中资源的调度策略可以为 FIFO 或 DRF (Dominant Resource Fairness),多用户下,为防止同一个用户提交的作业独占队列的所有资源,Capacity Scheduler 对每个用户可提交的作业可分配的资源量进行了限制。
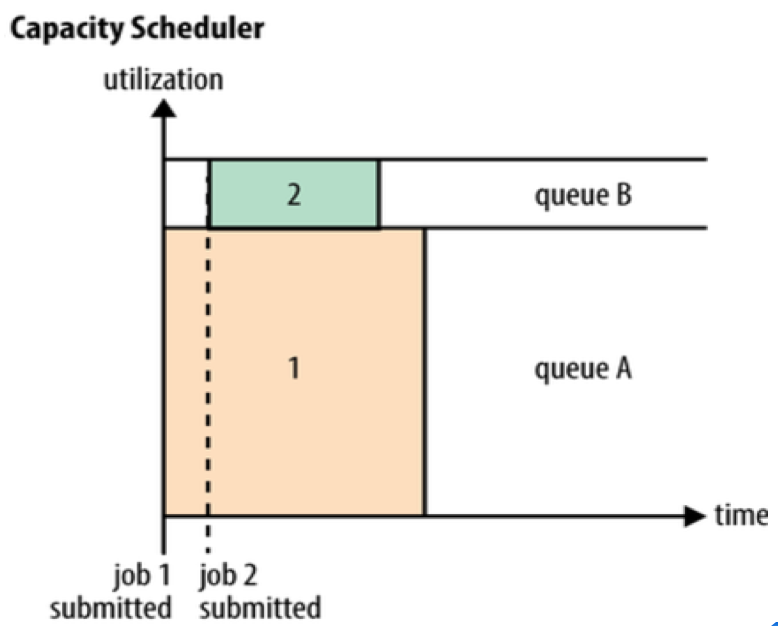
应用程序提交后,ResourceManager 会向 CapacityScheduler 发送一个事件,CapacityScheduler 收到后,将为应用程序创建一个对象跟踪和维护其运行时的信息,同时,将它提交到对应的叶子队列中,队列会对应用程序进行合法性检查。通过检查,应用程序才算提交成功。提交成功后,它的ApplicationMaster会为它申请资源,CapacityScheduler收到资源申请后,暂时将这些请求存放到一个数据结构中,以等待为其分配合适的资源。
NodeManager 发送的心跳信息有两类需要 CapacityScheduler 处理:一类是最新启动的 Container;另一类是运行完成的 Container。CapacityScheduler 将回收它使用的资源进行再分配。CapacityScheduler 采用三级资源分配策略(即将双层调度机制中的第一层分为选择队列与选择应用程序两级),当一个节点上有空闲资源时,它会依次选择队列、应用程序和 Container (请求)使用该资源,接下来介绍三级资源分配策略。
第一级:选择队列。CapacityScheduler 采用基于优先级的深度优先遍历算法选择队列:从根队列开始,按照资源使用率由小到大遍历子队列。如果子队列是叶子队列,则按照第二、三级的方法在队列中选择一个 Container,否则以该队列为根队列,重复以上过程,直到找到合适的 Container 并退出。
第二级:选择应用程序。选中一个叶子队列后,CapacityScheduler 按照ApplicationID 对叶子队列中的应用程序进行排序,依次遍历排序后的应用程序,找到合适的 Container。
第三级:选择 Container。选中一个应用程序后,先满足优先级高的Container。同一优先级,先满足本地化的 Container,依次选择节点本地化、机架本地化和非本地化的 Container。
Fair 调度算法
- 每个队列有权重元素,用于fair share的计算。
- 默认队列和动态创建的队列,权重为1(默认队列的可配置)。
- 调度器会使用最小资源数量来进行资源分配进行优先排序。如果两个队列的资源都低于fair share额度,那么远低于最小资源数量的队列,会被有限分配资源。
Fair Scheduler 是 Facebook 开发的多用户调度器,同 Capacity Scheduler 相似,都以队列为单位划分资源,且每个队列可设定一定比例的资源最低保证和使用上限。Facebook 设计 Fair Scheduler 算法的初衷是让 Hadoop 平台可以更高效的处理不同类型的作业,最大化的保证了系统中各作业能够分配到的系统资源 。如果当前集群中只有一个作业,则该作业会独占整个集群中全部系统资源。当有新的作业被提交至系统时,一些任务会在完成后将资源分配给新提交的作业,Fair Scheduler 会尽量保证各作业间可以获得基本相同的系统资源,从而保证短作业具有较短的响应时间。
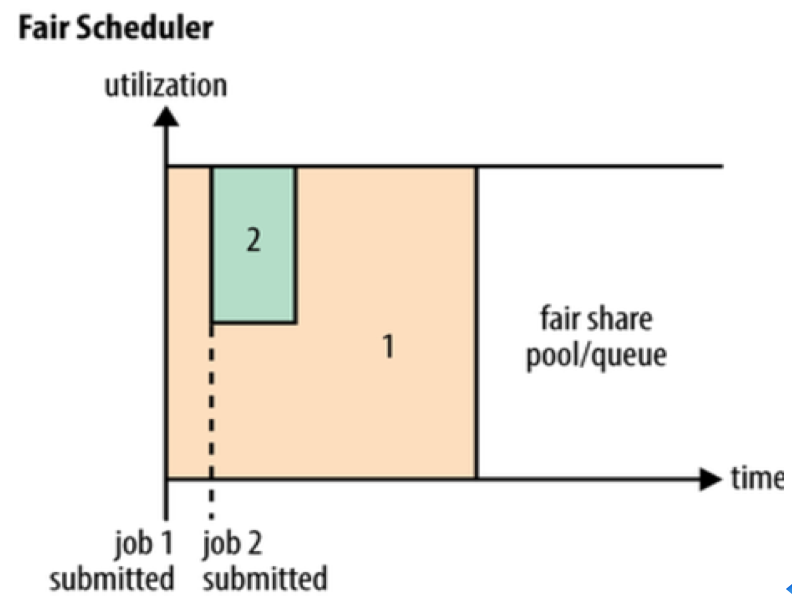
与CapacityScheduler不同的是,FairScheduler 提供了更多样化的调度策略,调度策略在队列间和队列内部可单独设置。当前有三种策略可选,分别是先来先服务(FIFO)、公平调度(Fair)和主资源公平调度(Dominant ResourceFairness,DRF)。
- 先来先服务:按优先级高低调度,优先级相同,则按提交时间先后顺序调度;提交时间相同,则按名称大小调度。
- 公平调度:按内存资源使用比率大小调度。
- 主资源公平调度:按主资源公平调度算法进行调度,所需份额最大的资源称为主资源,把最大最小公平算法应用于主资源上,将多维资源调度问题转化为单资源调度问题。
DRF算法伪代码:
1 | R = <r1, ··· , rm> //m种资源对应容量 |
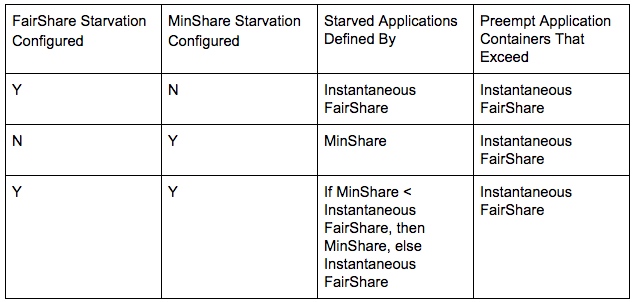
饥饿和抢占
FairShare的计算会被用于判断饥饿以及是否进行抢占。在计算FairShare时,有两种:
- Steady FairShare,按照配置文件中所有queue的weight,计算出的。
- Instantaneous FairShare,,按照配置文件中所有queue的weight,仅对包含活动应用程序的queue计算出的。
在配置yarn.scheduler.fair.preemption和yarn.scheduler.fair.preemption.cluster-utilization-threshold后,抢占会启用。
饥饿有两种:
- FairShare Starvation
要注意的是,在同一个队列里面,如果存在多个应用程序,它们会平均的分摊Instantaneous FairShare。因此可能存在队列整体不是饥饿状态,但是每个应用程序是。
判定条件为:- 未获得所要求的资源。
- 应用程序资源使用低于Instantaneous FairShare。
- 应用程序的资源使用低于fairSharePreemptionThreshold,并持续fairSharePreemptionTimeout。
- MinShare Starvation
判定条件为:- 未获得所要求的资源。
- 应用程序资源使用低于MinShare。
- 应用程序的资源使用低于MinShare,并持续MinSharePreemptionTimeout。
决定需要进行抢占的时候,可能在多个队列中都有可抢占的container,决定container是否可以被抢占,需要满足:
- 所在队列是可抢占的。
- 杀死container以后不会导致应用程序的资源低于Instantaneous FairShare。
启用抢占并不能保证队列或应用程序能够获得所有的Instantaneous FairShare。只能最终保证脱离饥饿的状态,即获得fairSharePreemptionThreshold份额的资源。
FairShare Starvation、MinShare Starvation以及抢占的关系如下: