图像特征
LBP特征
基本概念
LBP(Local Binary Pattern,局部二值模式)是一种用来描述图像局部纹理特征的算子;它具有旋转不变性和灰度不变性等显著的优点。
原始的LBP算子定义为在3_3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3_3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。
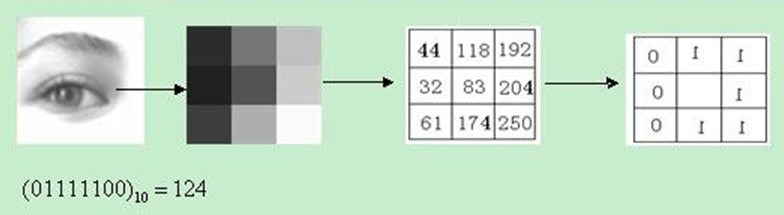
用比较正式的公式来定义的话: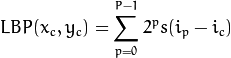
其中
代表3x3邻域的中心元素,它的像素值为ic,ip代表邻域内其他像素的值。s(x)是符号函数,定义如下:%!(EXTRA markdown.ResourceType=, string=, string=)
改进-圆形算子
基本的 LBP算子的最大缺陷在于它只覆盖了一个固定半径范围内的小区域,这显然不能满足不同尺寸和频率纹理的需要。为了适应不同尺度的纹理特征,并达到灰度和旋转不变性的要求,Ojala等对 LBP 算子进行了改进,将 3×3邻域扩展到任意邻域,并用圆形邻域代替了正方形邻域,改进后的 LBP 算子允许在半径为 R 的圆形邻域内有任意多个像素点。从而得到了诸如半径为R的圆形区域内含有P个采样点的LBP算子
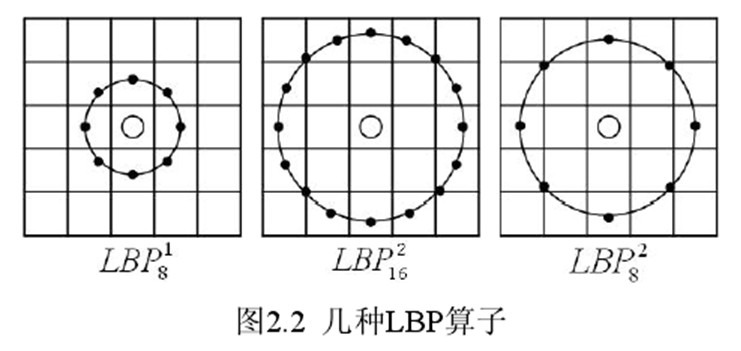
每个采样点的值可以通过下式计算:
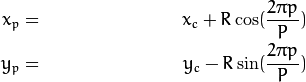
其中
为邻域中心点,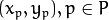
为某个采样点。通过上式可以计算任意个采样点的坐标,但是计算得到的坐标未必完全是整数,所以可以通过双线性插值来得到该采样点的像素值:
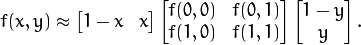
改进-旋转不变
从 LBP 的定义可以看出,LBP 算子是灰度不变的,但却不是旋转不变的。图像的旋转就会得到不同的 LBP值。
Maenpaa等人又将 LBP算子进行了扩展,提出了具有旋转不变性的 LBP 算子,即不断旋转圆形邻域得到一系列初始定义的 LBP值,取其最小值作为该邻域的 LBP 值。
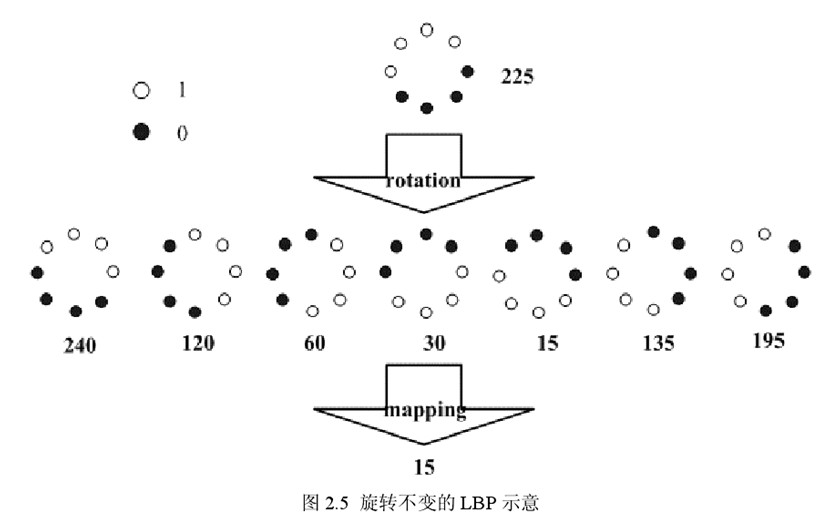
图中算子下方的数字表示该算子对应的 LBP值,图中所示的 8 种 LBP模式,经过旋转不变的处理,最终得到的具有旋转不变性的 LBP值为 15。也就是说,图中的 8种 LBP 模式对应的旋转不变的 LBP模式都是 00001111。
改进-等价模式
经统计,在实际图像中,绝大多数LBP模式最多只包含两次从1到0或从0到1的跳变。故将只有0次变化和2次变化的LBP二进制模式定义为的等价模式(当某个局部二进制模式所对应的循环二进制数从0到1或从1到0最多有两次跳变时,该局部二进制模式所对应的二进制就成为一个等价模式类。如0000 0000,1111 1111,1000 0111都是等价模式类)。
LBP特征使用方式
对一幅图像(记录的是每个像素点的灰度值)提取其原始的LBP算子之后,得到的原始LBP特征依然是“一幅图片”(记录的是每个像素点的LBP值)。
LBP的应用中,如纹理分类、人脸分析等,一般都不将LBP图谱作为特征向量用于分类识别,而是采用LBP特征谱的统计直方图作为特征向量用于分类识别。
对LBP特征向量进行提取的步骤
- 首先将检测窗口划分为16×16的小区域(cell);
- 对于每个cell中的一个像素,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数,即得到该窗口中心像素点的LBP值;
- 然后计算每个cell的直方图,即每个数字(假定是十进制数LBP值)出现的频率;然后对该直方图进行归一化处理。
- 最后将得到的每个cell的统计直方图进行连接成为一个特征向量,也就是整幅图的LBP纹理特征向量;
然后便可利用SVM或者其他机器学习算法进行分类了。
低频均值哈希
一张图片就是一个二维信号,它包含了不同频率的成分。亮度变化小的区域是低频成分,它描述大范围的信息。而亮度变化剧烈的区域(比如物体的边缘)就是高频的成分,它描述具体的细节。或者说高频可以提供图片详细的信息,而低频可以提供一个框架。
而一张大的,详细的图片有很高的频率,而小图片缺乏图像细节,所以都是低频的。所以我们平时的下采样,也就是缩小图片的过程,实际上是损失高频信息的过程。下面5张图依次是原图,放缩至6464、3232、1616、88的图。




均值哈希算法主要是利用图片的低频信息,其工作过程如下:
- 缩小尺寸:去除高频和细节的最快方法是缩小图片,将图片缩小到8x8的尺寸,总共64个像素。不要保持纵横比,只需将其变成8*8的正方形。这样就可以比较任意大小的图片,摒弃不同尺寸、比例带来的图片差异。
- 简化色彩:将8*8的小图片转换成灰度图像。
- 计算平均值:计算所有64个像素的灰度平均值。
- 比较像素的灰度:将每个像素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
- 计算hash值:将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的次序并不重要,只要保证所有图片都采用同样次序就行了。(我设置的是从左到右,从上到下用二进制保存)。
计算一个图片的hash指纹的过程就是这么简单。如果图片放大或缩小,或改变纵横比,结果值也不会改变。增加或减少亮度或对比度,或改变颜色,对hash值都不会太大的影响。最大的优点:计算速度快!这时候,比较两个图片的相似性,就是先计算这两张图片的hash指纹,也就是64位0或1值,然后计算不同位的个数(汉明距离)。如果这个值为0,则表示这两张图片非常相似,如果汉明距离小于5,则表示有些不同,但比较相近,如果汉明距离大于10则表明完全不同的图片。
pHash
pHash是低频均值哈希的增强版
一个基于pHash算法的、使用es的、从大批图片中快速检索相似图片的解决方案
理论依据为《AN IMAGE SIGNATURE FOR ANY KIND OF IMAGE》H. Chi Wong, Marshall Bern, and David Goldberg 这篇论文。
这篇论文介绍的算法有良好的普适性和鲁棒性,在处理图像文本、卡通图片、连续色调图片都有不错的效果。
图片签名计算
- 将图片转化为256级灰度图片,简化图片的色彩属性
- 取图片5%
95%的位置,划分为9*9的网格(之所以取5%95%,是因为考虑到扫描图片、被剪辑过的图片等,边缘部分的信息可能会干扰图片的识别)。

- 计算每个网格的平均灰度。计算方法为在网格内隔P个像素取一个点,取灰度均值。P的计算方法在论文内。
- 计算每个网格和相邻网格灰度的差值。分为5个等级:暗很多,暗一点,一样,亮一点,亮很多得到一个998的数组(有的算法是划分3个等级,例如均值哈希,5个等级可以更好的区分,也可以在一定程度上避免由于四舍五入产生的误差)
- 把数组按照某个规则打平,变为一维数组。规则不重要,只要保证每张图片都按相同的规则打平就行。
这个矩阵就是这张图片的签名。
对比两个矩阵,可以计算汉明距离,也可以计算欧氏距离.相比汉明距离,欧氏距离可以更加反映出图片的不同,而且第4步中刻意划分出5个等级,也是为了服务欧氏距离的计算。0.6的阈值是一个经验值,这个阈值在大多数情况下适用。超过0.6标识两张图片一点也不相关。
检索
如何快速从众多签名中检索出相似度高的签名,方案:将打平的图像签名切成一个一个的“词”,这些词可以重叠也可以不连续。但每张图片都要按照相同的规则切词。
例如数组 [0, 1, 2, 0, -1, -2, 0, 1],按照k=3(每个词3个值),N=4(切4个词),可以切为
[0, 1, 2]
[2, 0, -1]
[-1, -2, 0]
[0, 1]
然后将这些切好的词通过矩阵乘法转化为int值,存入es中,这些“词”就是图片用于检索的签名。
当需要检索某张图片时,现将这个图片的simple_words算出,然后去es中检索,如果存在相同位置数字相同的签名,那这两张图片就有相同的可能性。
论文中推荐的切法为k=10,N=100,image-match中的切法为k=16,N=63.
存在重叠的切词有一个好处,就是接受了图片局部不相似的容错性。同时N不宜过大。因为N越大,图片至少有一个simple_word相同的可能性就越大,这样的话可能找出很多只是碰巧有一个词相同的图片,降低了搜索效率。